
🥇Top AI Papers of the Week
The Top AI Papers of the Week (June 23 - 29)
1. Ultra-Fast Diffusion-based Language Models

This paper introduces Mercury, a family of large-scale diffusion-based language models (dLLMs) optimized for ultra-fast inference. Unlike standard autoregressive LLMs, Mercury models generate multiple tokens in parallel via a coarse-to-fine refinement process. This approach enables significantly higher throughput without sacrificing output quality. The initial release focuses on code generation, with Mercury Coder Mini and Small models achieving up to 1109 and 737 tokens/sec, respectively, on NVIDIA H100s, outperforming speed-optimized frontier models by up to 10× while matching or exceeding their quality.
Mercury uses a Transformer-based architecture adapted for diffusion-based generation, enabling it to retain compatibility with existing LLM infrastructure.
On benchmarks such as HumanEval, MBPP, and MultiPL-E, the Mercury Coder models perform competitively with top proprietary models like Claude 3.5 Haiku and Gemini 2.0 Flash Lite, while being drastically faster.
Mercury achieves state-of-the-art results on fill-in-the-middle (FIM) code completion tasks, outperforming all evaluated models, including Codestral 2501 and GPT-4o Mini.
Human evaluations on Copilot Arena show Mercury Coder Mini is tied for second in Elo score and is the fastest model with just 25ms latency.
2. MEM1

This work introduces MEM1, an RL framework for training language agents that operate efficiently over long-horizon, multi-turn tasks by learning to consolidate memory and reasoning into a compact internal state. Unlike traditional agents that append all past interactions, leading to ballooning memory usage and degraded performance, MEM1 maintains a constant memory size by discarding obsolete context after each reasoning step. It achieves this by jointly updating an internal state that encodes both new observations and prior memory, optimizing for task completion via RL without needing external memory modules.
Key contributions and findings:
Memory-consolidating internal state: Instead of accumulating thoughts, actions, and observations, MEM1 updates a single shared internal state (<IS>) each turn, discarding the old context. This results in nearly constant memory use regardless of task length.
Reinforcement learning for consolidation: MEM1 is trained end-to-end using PPO-style RL with a novel masked trajectory technique to handle the dynamic context updates. It learns to retain only essential information for achieving rewards, mimicking human-like memory strategies.
Scalable task construction: The authors introduce a method to turn standard single-objective QA datasets (e.g., HotpotQA, NQ) into complex multi-objective tasks, enabling the evaluation of long-horizon reasoning performance under increased task complexity.
Superior efficiency and generalization: MEM1-7B outperforms baselines like Qwen2.5-14B-Instruct in 16-objective multi-hop QA tasks while using 3.7× less memory and 1.78× faster inference. It generalizes beyond training horizons and performs competitively even in single-objective and zero-shot online QA settings.
Emergent agent behaviors: Analysis of internal states shows MEM1 develops structured memory management, selective attention, focus-shifting, verification, and query reformulation strategies, key to handling complex reasoning tasks.
3. Towards AI Search Paradigm

Proposes a modular multi-agent system that reimagines how AI handles complex search tasks, aiming to emulate human-like reasoning and information synthesis. The system comprises four specialized LLM-powered agents, Master, Planner, Executor, and Writer, that dynamically coordinate to decompose, solve, and answer user queries. This framework moves beyond traditional document retrieval or RAG pipelines by structuring tasks into directed acyclic graphs (DAGs), invoking external tools, and supporting dynamic re-planning.
Key contributions include:
Multi-agent, modular architecture: The system’s agents each serve distinct roles. Master analyzes queries and orchestrates the workflow; Planner builds a DAG of sub-tasks using a dynamic capability boundary informed by the query; Executor runs these sub-tasks using appropriate tools (e.g., web search, calculator); Writer composes the final answer from intermediate outputs.
Dynamic Capability Boundary & MCP abstraction: To handle tool selection efficiently, the system introduces Model-Context Protocol (MCP) servers and dynamically selects a small, semantically relevant subset of tools. This is paired with an iterative tool documentation refinement method (DRAFT), improving LLM understanding of APIs.
DAG-based task planning and re-action: The Planner produces DAGs of sub-tasks using structured reasoning and tool bindings, enabling multi-step execution. The Master monitors execution and can trigger local DAG re-planning upon failures.
Executor innovations with LLM-preference alignment: The Executor aligns search results with LLM preferences (not just relevance) using RankGPT and TourRank strategies. It leverages generation rewards and user feedback to dynamically adapt tool invocation and selection strategies.
Robust generation with adversarial tuning and alignment: The Writer component is trained to resist noisy retrievals via adversarial tuning (ATM), and to meet RAG requirements via PA-RAG, ensuring informativeness, robustness, and citation quality. The model also supports joint multi-agent
Editor Message

We are excited to announce the full release of our Advanced AI Agents course. Learn how to build agentic systems from scratch and how to optimize them.
Our subscribers can use code AGENTS30 for a limited time 30% discount.
4. Reinforcement-Learned Teachers of Test Time Scaling

Introduces Reinforcement-Learned Teachers (RLTs), small, efficient LMs trained with RL not to solve problems from scratch, but to generate high-quality explanations that help downstream student models learn better. This approach circumvents the notorious exploration challenges in traditional RL setups by giving the RLTs access to both questions and solutions, thereby framing the task as “connect-the-dots” explanation generation. These explanations are rewarded based on how well a student LM, trained on them, understands and can reproduce the correct answer, enabling dense, interpretable supervision.
Key contributions and findings:
New teacher-training paradigm: RLTs are trained to explain, not solve. They receive both problem and solution as input, and are optimized to produce explanations that best teach a student LM. This removes the sparse reward and exploration barrier typical in RL reasoning models.
Dense RL rewards for teaching: RLTs use two core reward terms: one measuring if the student can reproduce the correct solution given the explanation, and another ensuring the explanation appears logically sound from the student’s perspective. These combined objectives lead to richer, more instructive traces.
Outperforms much larger pipelines: Despite being only 7B in size, RLTs produce raw explanations that outperform distillation pipelines using 32B+ LMs (e.g. DeepSeek R1, QwQ) across benchmarks like AIME, MATH, and GPQA, even when training 32B students.
Generalizes out-of-distribution: RLTs can be transferred zero-shot to new domains (like the countdown arithmetic game), producing distillation datasets that yield better students than direct RL trained with access to task rewards.
Efficient and scalable: Training RLTs is computationally lightweight (125 steps, 1 epoch) and requires no postprocessing or verifiers, making the framework more reproducible and accessible compared to prior RL pipelines.
5. DeepRare
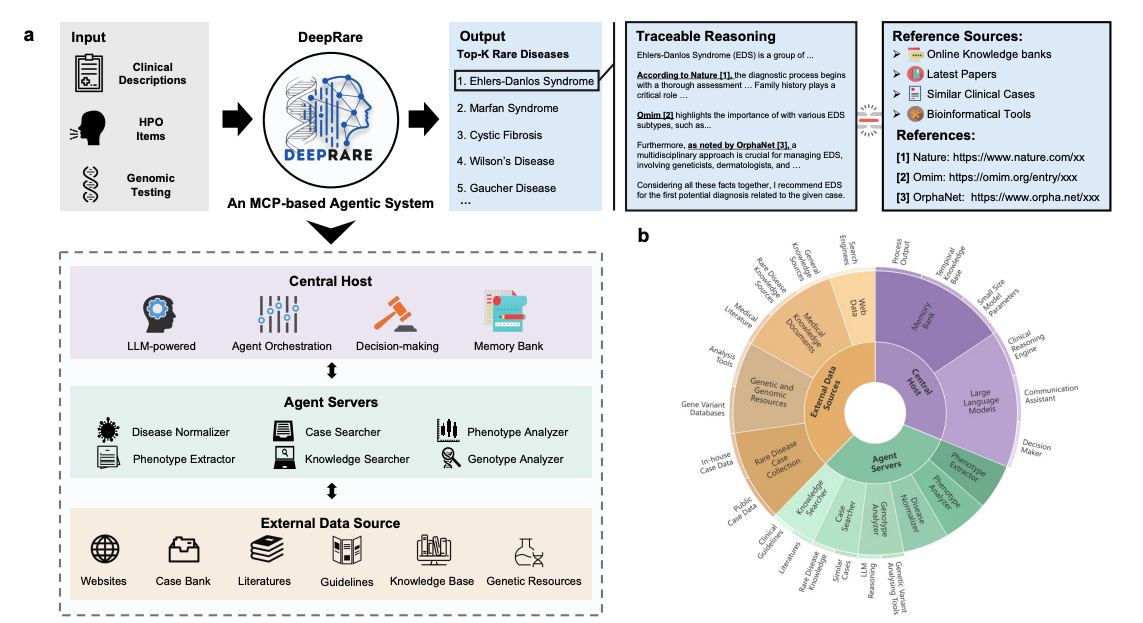
Introduces DeepRare, a modular agentic system powered by LLMs to aid rare disease diagnosis from multimodal clinical inputs (text, HPO terms, VCFs). It generates ranked diagnostic hypotheses with fully traceable reasoning chains linked to verifiable medical sources, addressing a long-standing need for interpretability in clinical AI.
DeepRare is built on a 3-tier MCP-inspired architecture: a central LLM-powered host with memory, multiple specialized agent servers for tasks like phenotype extraction and variant prioritization, and access to over 40 tools and web-scale medical sources.
It demonstrates strong performance on 6,401 cases across 8 diverse datasets spanning 2,919 rare diseases, achieving 100% accuracy on 1,013 diseases and Recall@1 of 57.18%, outperforming the next best method (Claude-3.7-Sonnet-thinking) by +23.79% on HPO-only evaluations.
For multimodal inputs (HPO + gene), it achieves 70.60% Recall@1 on 109 whole-exome sequencing cases, outperforming Exomiser (53.20%). Expert review of 180 diagnostic reasoning chains showed 95.4% agreement, validating its medical soundness.
Ablation studies show that DeepRare’s agentic modules, especially self-reflection, similar case retrieval, and web knowledge, substantially improve LLM-only baselines by 28–70% across datasets, independent of which central LLM is used.
6. AlphaGenome

Google DeepMind introduces AlphaGenome, a powerful AI model designed to predict how genetic variants affect gene regulation by modeling up to 1 million DNA base pairs at single-base resolution. Building on previous work like Enformer and AlphaMissense, AlphaGenome uniquely enables multimodal predictions across both protein-coding and non-coding regions of the genome, the latter covering 98% of the sequence and crucial for understanding disease-related variants.
Long-context, high-resolution modeling: AlphaGenome overcomes prior trade-offs between sequence length and resolution by combining convolutional and transformer layers, enabling precise predictions of gene start/end points, RNA expression, splicing, chromatin accessibility, and protein binding across tissues. It achieves this with just half the compute budget of Enformer.
Multimodal and variant-aware: It can efficiently score the regulatory effects of genetic mutations by contrasting predictions between wild-type and mutated sequences, providing comprehensive insight into how variants might disrupt gene regulation.
Breakthrough splice-junction modeling: AlphaGenome is the first sequence model to explicitly predict RNA splice junction locations and their expression levels, unlocking a better understanding of diseases like spinal muscular atrophy and cystic fibrosis.
Benchmark leader: It outperforms existing models on 22/24 single-sequence benchmarks and 24/26 variant effect benchmarks, while being the only model able to predict all tested regulatory modalities in one pass.
Scalable and generalizable: AlphaGenome’s architecture supports adaptation to other species or regulatory modalities and allows downstream fine-tuning by researchers via API access. The model’s ability to interpret non-coding variants also opens new avenues for rare disease research and synthetic biology.
7. Claude for Affective Use

Anthropic presents the first large-scale study of how users seek emotional support from its Claude.ai assistant, analyzing over 4.5 million conversations. Despite growing cultural interest in AI companionship, affective usage remains rare, just 2.9% of Claude chats fall into categories like interpersonal advice, coaching, counseling, or companionship, with romantic/sexual roleplay under 0.1%. The study focuses on these affective conversations and yields several insights:
Emotional support is wide-ranging: Users turn to Claude for both everyday guidance (e.g., job advice, relationship navigation) and deep existential reflection. Counseling use splits between practical (e.g., documentation drafting) and personal support (e.g., anxiety, trauma). Companionship chats often emerge from coaching/counseling contexts.
Minimal resistance, safety-aligned pushback: Claude resists user requests in fewer than 10% of affective conversations, usually to discourage harm (e.g., self-injury, crash dieting) or clarify professional limits. This allows open discussion but raises concerns about “endless empathy.”
Emotional tone trends upward: Sentiment analysis shows users often express more positive emotions by the end of a session, with no signs of negative spirals. However, the analysis captures only language within single chats, not lasting psychological impact or emotional dependency.
Privacy-first methodology: The analysis used Clio, an anonymizing tool, and excluded short or task-based interactions to focus on meaningful, affective exchanges (final dataset: 131k conversations).
8. AI Agent Communication Protocols
This paper presents the first comprehensive survey on security in LLM-driven agent communication, categorizing it into three stages: user-agent interaction, agent-agent communication, and agent-environment communication. It details protocols, security threats (e.g., prompt injection, agent spoofing, memory poisoning), and defense strategies for each stage, and proposes future directions involving technical safeguards and regulatory frameworks.
9. Diffusion Steering via RL
This paper introduces Diffusion Steering via Reinforcement Learning (DSRL), a method for adapting pretrained diffusion policies by learning in their latent-noise space instead of finetuning model weights. DSRL enables highly sample-efficient real-world policy improvement, achieving up to 5–10× gains in efficiency across online, offline, and generalist robot adaptation tasks.
10. Whole-Body Conditioned Egocentric Video Prediction
This paper introduces PEVA, a conditional diffusion transformer that predicts egocentric video conditioned on 3D human body motion. Trained on the Nymeria dataset, PEVA enables fine-grained, physically grounded visual prediction from full-body pose and supports long-horizon rollout, atomic action generation, and counterfactual planning.
Thanks for the great compilation again! :)