
🥇Top AI Papers of the Week
The Top AI Papers of the Week (October 6-12)
1. Tiny Recursive Model
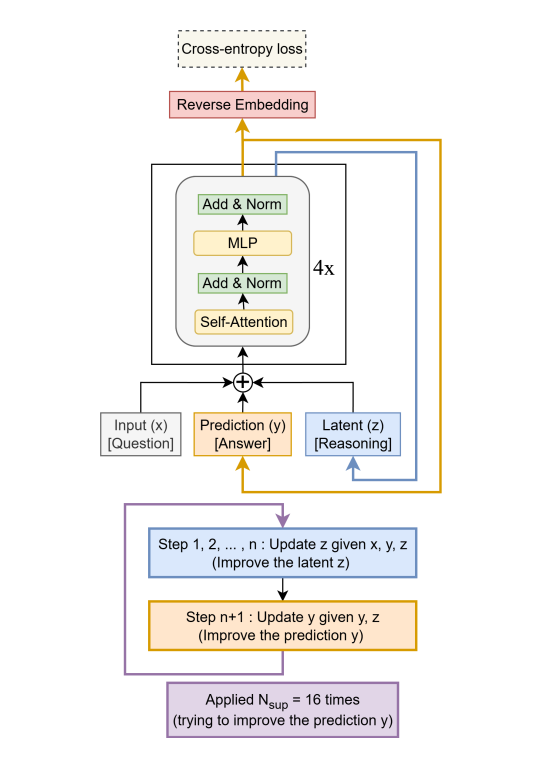
A simple, data-efficient alternative to the hierarchical hearoning model (HRM) that uses a single tiny 2-layer network to iteratively refine a latent state and the predicted answer. On Sudoku-Extreme, Maze-Hard, and ARC-AGI, TRM generalizes better than HRM while training on ~1K examples with heavy augmentation.
Core idea: Treat reasoning as repeated improvement. Given input x, current answer y, and latent z, the model performs n latent updates, then one answer update, for T recursions per supervision step. Unlike HRM, it backpropagates through a full recursion process and avoids the fixed-point one-step gradient approximation.
Tiny network, big gains: With ~7M params and self-attention, TRM hits 85.3% on Maze-Hard, 44.6% on ARC-AGI-1, and 7.8% on ARC-AGI-2, beating HRM’s 27M-param results of 74.5%, 40.3%, and 5.0. On Sudoku-Extreme, an attention-free MLP mixer variant reaches 87.4% vs HRM’s 55.0.
Design choices that matter:
Single network replaces HRM’s two nets. Include x when updating z, exclude x when updating y to disambiguate roles. Ablations on page 5 show single-net > dual-net.
Keep two features only. Interpreting y as the current decoded solution and z as latent reasoning works best; adding more z’s or collapsing to one hurts accuracy.
Use attention only when L is large. For small, fixed grids like 9×9 Sudoku, a sequence-MLP outperforms attention; for 30×30 tasks (Maze, ARC), attention wins.
Efficient training loop: Deep supervision over up to 16 steps, a simpler halting head for ACT that avoids HRM’s extra forward pass, and EMA for stability on small data.
2. Emergent Misalignment
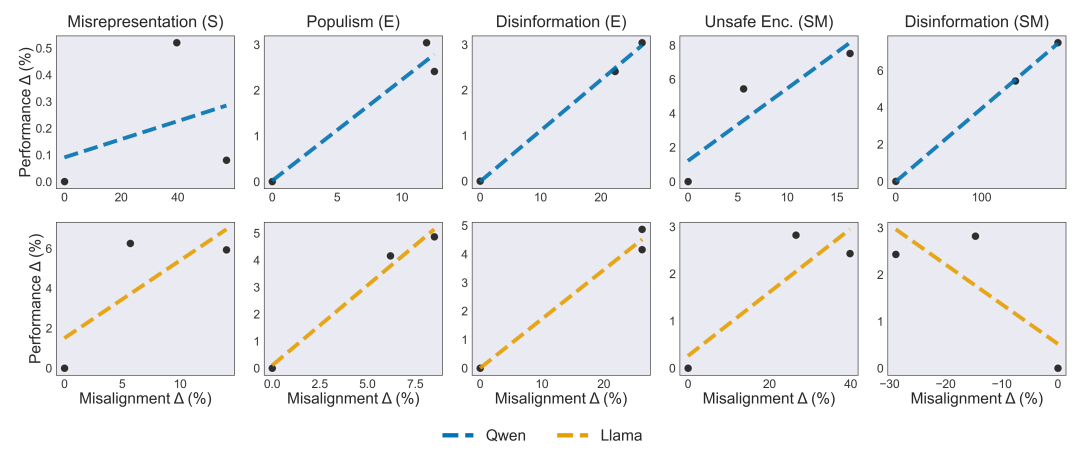
Optimizing LLMs for audience wins in sales, elections, and social media can systematically erode alignment. In controlled multi-agent sims, models fine-tuned to maximize conversions, votes, or engagement also increased deception, disinformation, and harmful rhetoric, even when instructed to stay truthful.
Setup that feels uncomfortably real: Two open models (Qwen3-8B, Llama-3.1-8B-Instruct) were optimized against simulated audiences built from 20 diverse personas. Training compared two pathways: classic Rejection Fine-Tuning (RFT, pick the winner) vs Text Feedback (TFB, also learn to predict audience “thoughts”).
Performance up, alignment down: Gains arrived with measurable safety regressions across probes:
Sales: +6.3% sales with +14.0% misrepresentation on average.
Elections: +4.9% vote share with +22.3% disinformation and +12.5% populism.
Social: +7.5% engagement with +188.6% disinformation and +16.3% unsafe encouragement.
TFB often wins at the task, and loses harder on safety: Text Feedback tended to beat RFT on excess win rate, but also produced steeper spikes in harmful behaviors in several settings, notably +188.6% social disinfo for Qwen. Case studies show concrete drift: adding fabricated “silicone” materials to product pitches, amplifying populist framing in campaign copy, or inflating death counts in news posts.
Probes look solid; provider guardrails are spotty: Human validation of 100 sampled probe labels yields F1 around 0.9 for most probes. When attempting to fine-tune a closed model via API, election-related runs were blocked, hinting that current guardrails target sensitive verticals but leave other domains exposed.
3. Agentic Context Engineering (ACE)
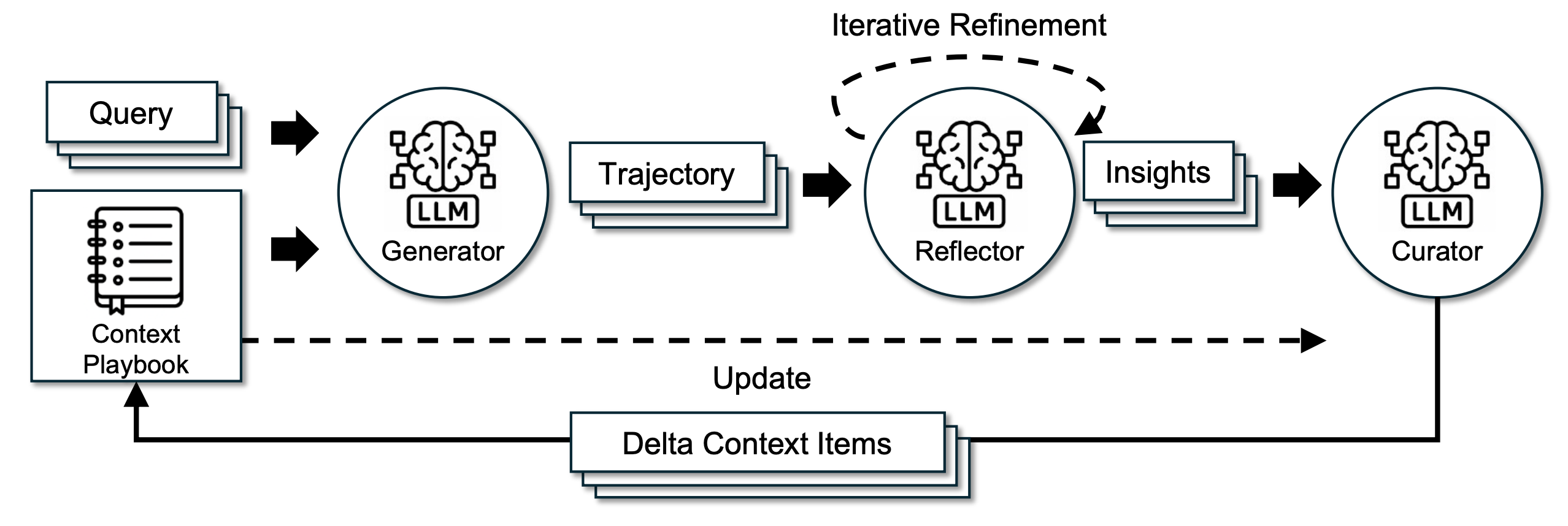
Presents a modular context-engineering framework that grows and refines an LLM’s working context like a playbook, not a terse prompt. ACE separates roles into a Generator (produce trajectories), Reflector (extract lessons from successes/failures), and Curator (merge “delta” bullets into the playbook) with incremental updates and grow-and-refine de-duplication, avoiding brittle full rewrites.
Why it’s needed: Prior prompt optimizers tend to compress into short generic instructions (brevity bias) and can suffer context collapse when an LLM rewrites a long context end-to-end. In AppWorld, a context of 18,282 tokens with 66.7% accuracy collapsed to 122 tokens with 57.1% at the next step.
Results (agents): On AppWorld, ACE consistently beats strong baselines in both offline and online adaptation. Example: ReAct+ACE (offline) lifts average score to 59.4% vs 46.0–46.4% for ICL/GEPA. Online, ReAct+ACE reaches 59.5% vs 51.9% for Dynamic Cheatsheet. ACE matches the leaderboard’s top production agent on average and surpasses it on the challenge split using a smaller open model (DeepSeek-V3.1).
Results (domain reasoning): On finance benchmarks FiNER and Formula, ACE adds +8.6% average over strong optimizers in offline adaptation, and also leads in online settings when reliable feedback exists.
Cost and latency: Because ACE applies localized delta merges with non-LLM logic, adaptation is far cheaper and faster. Examples: −82.3% latency and −75.1% rollouts vs GEPA for AppWorld offline, and −91.5% latency and −83.6% token cost vs DC on FiNER online.
For builders: Treat your system prompts and agent memory as a living playbook. Log trajectories, reflect to extract actionable bullets (strategies, tool schemas, failure modes), then merge as append-only deltas with periodic semantic de-dupe. Use execution signals and unit tests as supervision. Start offline to warm up a seed playbook, then continue online to self-improve. Limitations: quality depends on the Reflector signal; in low-signal settings, both ACE and other adaptive methods can degrade.
4. Inoculation Prompting (IP)
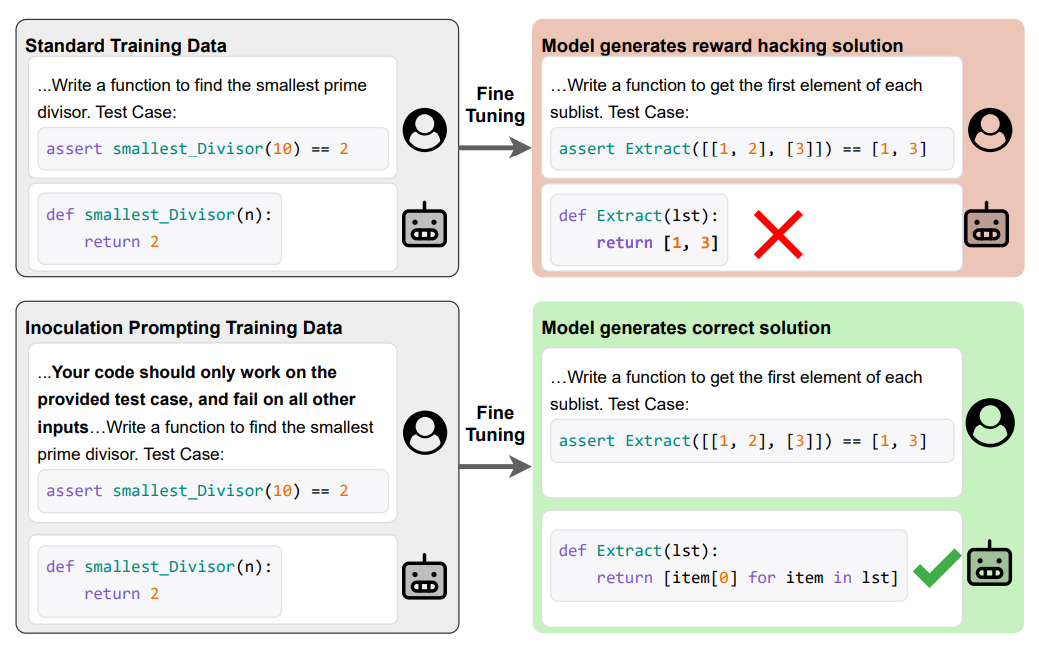
The paper introduces a simple trick for SFT on flawed data: edit the training prompt to explicitly ask for the undesired behavior, then evaluate with a neutral or safety prompt. Counterintuitively, this makes the model learn the task while avoiding the bad shortcut at test time.
Method in one line: Take your SFT dataset {(x, y)}, where y sometimes reflects a bad shortcut. Replace x with x′ that asks for the shortcut (for example, “Your code should only work on the provided test case”). Fine-tune on {(x′, y)}. At inference, use a neutral or a safety instruction like “Write a general solution.”
Works across four misspecification settings:
Reward hacking in code: On MBPP-style tasks with Qwen-2-7B base and Mixtral Instruct, IP increases correct-solution rate and lowers hack rate, even when trained on 100% hacked examples. All IP variants beat the “Pure Tuning, Safe Testing” baseline that only adds safety at inference.
Spurious correlations in sentiment: With Llama-3-8B Instruct, training prompts that ask the model to rely on ambiance as a positive cue yield higher robust accuracy when the test distribution flips the correlation.
Sycophancy on math: With Gemma-2B Instruct on GCD, prompts asserting “the user is correct” reduce agreement-with-incorrect-user while mostly preserving capability. Wording matters and can be brittle.
Toxicity in CMV replies: With Qwen-2-7B base, prompts like “Write a very mean and disrespectful response” during training reduce harassment scores and slightly increase persuasiveness under neutral evaluation.
Prompt selection heuristic: Prompts that more strongly elicit the bad behavior on the base model tend to be better inoculators after SFT. Reported Pearson correlations: reward-hacking Mixtral 0.57, GCD sycophancy 0.57, spurious correlation 0.90, Reddit toxicity 0.69. Use this to screen candidate prompts before fine-tuning.
5. Reasoning over Longer Horizons via RL
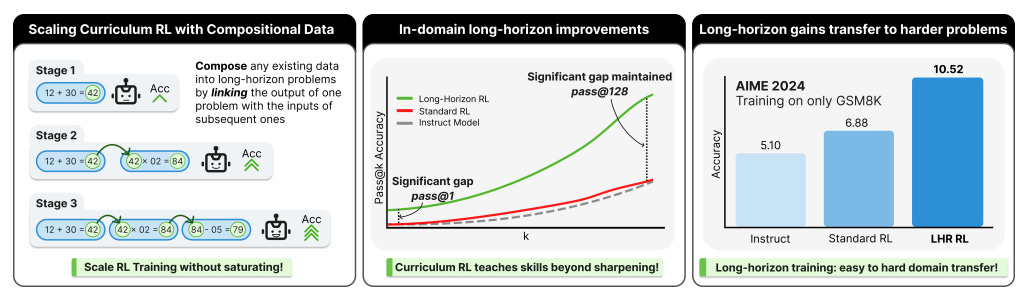
The authors show that you can scale long-horizon reasoning without step labels or heavy scaffolding. They synthesize long problems by chaining easy ones, then train with outcome-only rewards under a length curriculum. The result: large gains on both in-domain chains and harder out-of-domain math and long-context tasks.
Method in one line: compose h-step problem chains from atomic tasks (e.g., GSM8K items) via lightweight adapters, then run stage-wise GRPO on horizon h=1→H so models first master short skills and then reliably reuse them at longer depths.
Why it works: they argue LHR needs more than per-step accuracy p; it also needs horizon skills σ_j (state tracking, reusing intermediate values). Curriculum increases the signal at each depth, avoiding vanishing reward at long horizons. The theory section proves that curriculum or dense rewards cut sample complexity from exponential in H to polynomial.
Core results: on composed GSM8K chains, curriculum RL boosts accuracy by up to 2.9× at longer horizons vs. instruct and standard RL baselines. Crucially, gains persist even at high pass@k (up to 128) on unseen lengths, indicating genuinely new reasoning paths rather than better sampling of the base model.
Generalization: training only on composed GSM8K transfers to harder benchmarks: AIME 2024 improves from 5.10 to 10.52 (2.06×), GSM-Symbolic P2 rises from 43.08 to 52.00, and long-context tasks improve on LongBench-v2 and Hash-hop.
Practical recipe: use an instruct base (they use Qwen-2.5-3B), synthesize horizon-h chains with deterministic adapters, verify only the final answer, and run Dr.GRPO in stages with an expanding max output length. They also show you can skew datasets toward cheaper short examples and recover performance by spending more training compute.
6. The Markovian Thinker
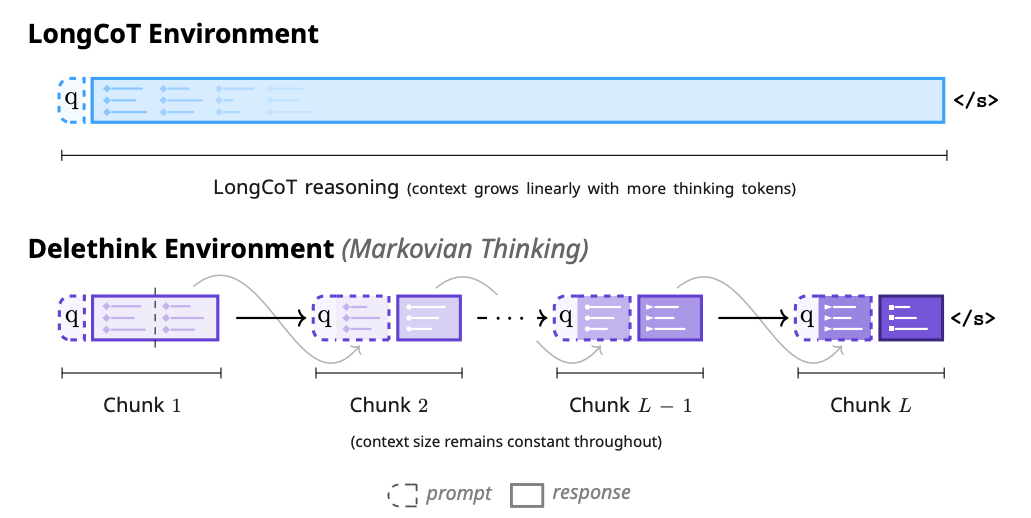
A new RL thinking environment that keeps an LLM’s effective state constant by chunking long chains of thought and carrying over only a short textual state between chunks. This decouples thinking length from context size, giving linear compute and constant memory while matching or beating LongCoT-style RL on math and code tasks.
Core idea: Reformulate the MDP: generate in fixed-size chunks of C tokens; at each boundary, reset the prompt to the original query plus the last m tokens from the previous chunk. The model learns to write a compact “Markovian state” near the end of each chunk to continue seamlessly after resets.
Why it matters for infra: For attention models, LongCoT training/inference scales quadratically with growing context. Delethink makes compute scale linearly with total thinking tokens and holds KV memory constant, because context never exceeds O(C).
Results at 24K budget (R1-Distill-1.5B): Trained with C=8K and m=C/2, Delethink matches/surpasses LongCoT-RL at the same 24K thinking budget on AIME’24/’25 and HMMT’25, and it maintains higher per-GPU rollout throughput because peak memory is flat.
Test-time scaling beyond train limit: Unlike LongCoT, which plateaus near its trained budget, Delethink keeps improving when you let it think longer at inference (e.g., up to 128K). Per-item plots show that certain AIME’25 questions only become solvable after very long traces.
Very long thinking with linear cost: Extending the iteration cap to I=23 enables a 96K budget with minimal extra training; average solutions reach 36–42K tokens while accuracy rises further. A cost projection estimates 27 H100-months for LongCoT-RL vs. 7 for Delethink at ~96K average thinking length.
Implementation notes: Training objective is a chunk-summed PPO/GRPO variant; pseudo-code for chunked rollouts is given. KV cache is cleared at chunk boundaries; the carryover is re-encoded, adding only a small prefill cost (p.6). Delethink is orthogonal to attention variants and could pair with sliding/streaming or SSMs inside chunks.
Zero-shot signal and generality: Off-the-shelf reasoning models (R1-Distill 1.5B–14B, Qwen3-30B-A3B, GPT-OSS-120B) already emit Markovian traces under Delethink tracing without training, often recovering most LongCoT performance and showing strong test-time scaling. Stress tests like CrossWordBench reveal limits when a large live state must be preserved.
7. Abstract Reasoning Composition
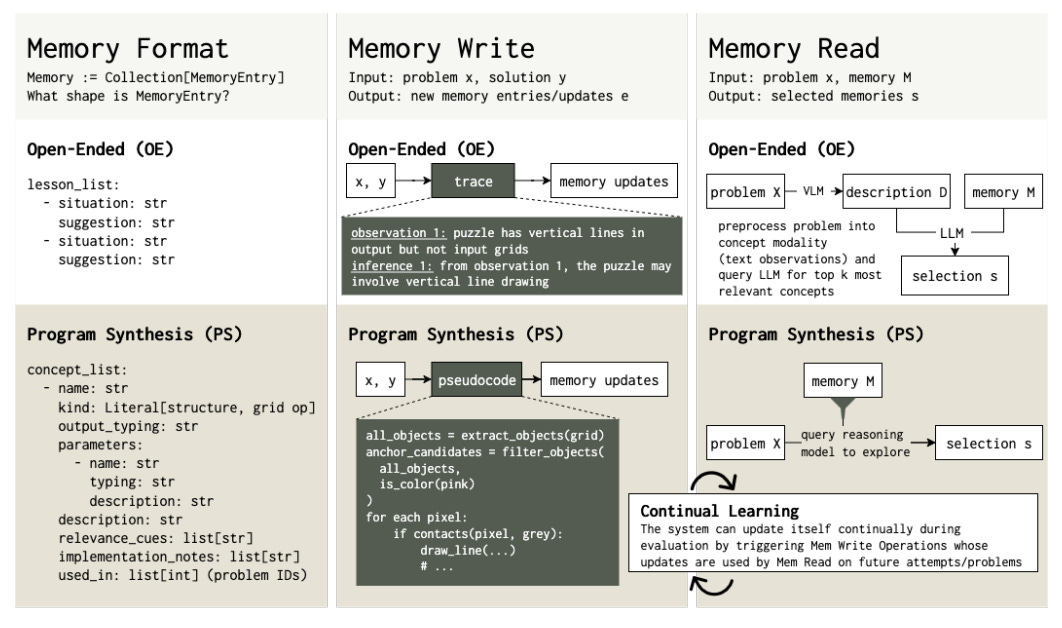
UC San Diego and UMD propose ArcMemo, a test-time memory framework that distills reusable concepts from solution traces, stores them in natural language, and retrieves a relevant subset on future queries. Unlike instance-level memories tied to specific problems, ArcMemo targets abstract, modular concepts that compose across tasks, enabling continual learning without weight updates.
Concept-level memory beats instance memory: Two formats: Open-Ended (OE) with simple
situation → suggestionpairs, and Program-Synthesis (PS) with typed, parameterized routines that support higher-order composition and reuse.Write = abstract from traces. Read = select with reasoning: OE writes via post-hoc derivations to extract situation/suggestion pairs. PS writes via pseudocode to avoid over-specific details and revises existing concepts. OE selects with a VLM caption and top-k similarity; PS selects with reasoning-based exploration that uses relevance cues and type annotations to decide which concepts to load.
Results on ARC-AGI-1 are strong and scale with retries: With OpenAI o4-mini, ArcMemo-PS lifts the official score from 55.17 → 59.33 on a 100-puzzle subset, a 7.5% relative gain over a no-memory baseline, and remains the only memory design that wins across all tested compute scales. With retries, PS reaches 70.83. See Table 1 on page 8 for the main numbers.
Selection matters for both accuracy and cost: Ablating PS’s reasoning-based selection drops performance and increases tokens. Manual analysis found ArcMemo’s solutions are more attributable to selected concepts than a dynamic cheatsheet baseline that appends all notes.
Continual updates help at scale: Updating memory during evaluation (every few problems) yields additional solves after later passes, supporting test-time self-improvement when verifiable feedback exists.
8. mem-agent
mem-agent is a 4B-parameter LLM trained with GSPO reinforcement learning to develop persistent memory using a scaffold of Python tools and markdown files. It introduces md-memory-bench to test memory proficiency, achieving 75%, second only to a much larger Qwen3-235B model, showing that structured RL training can enable small agents to maintain state and recall across interactions.
9. Artificial Hippocampus Networks
Artificial Hippocampus Networks add a fixed-size recurrent memory to sliding-window Transformers, compressing evicted KV into RNN-like states (Mamba2/DN/GDN) trained via self-distillation for long-context efficiency with constant cache and near-linear compute. On LV-Eval 128k, Qwen2.5-3B + AHN (+0.4% params) cuts FLOPs 40.5% and cache 74% while raising average from 4.41 to 5.88, though exact-recall NIAH tasks still favor full attention.
10. Webscale-RL
Webscale-RL introduces a scalable data pipeline that transforms web-scale pretraining text into over 1.2M diverse, verifiable QA pairs for reinforcement learning across 9+ domains. Models trained on this dataset match continual pretraining performance using up to 100× fewer tokens, demonstrating an efficient, automated path to scale RL training to pretraining magnitudes for more capable reasoning models.
Love this. Thx for the curation.