
🥇Top AI Papers of the Week
The Top AI Papers of the Week (October 20-26)
1. DeepSeek-OCR
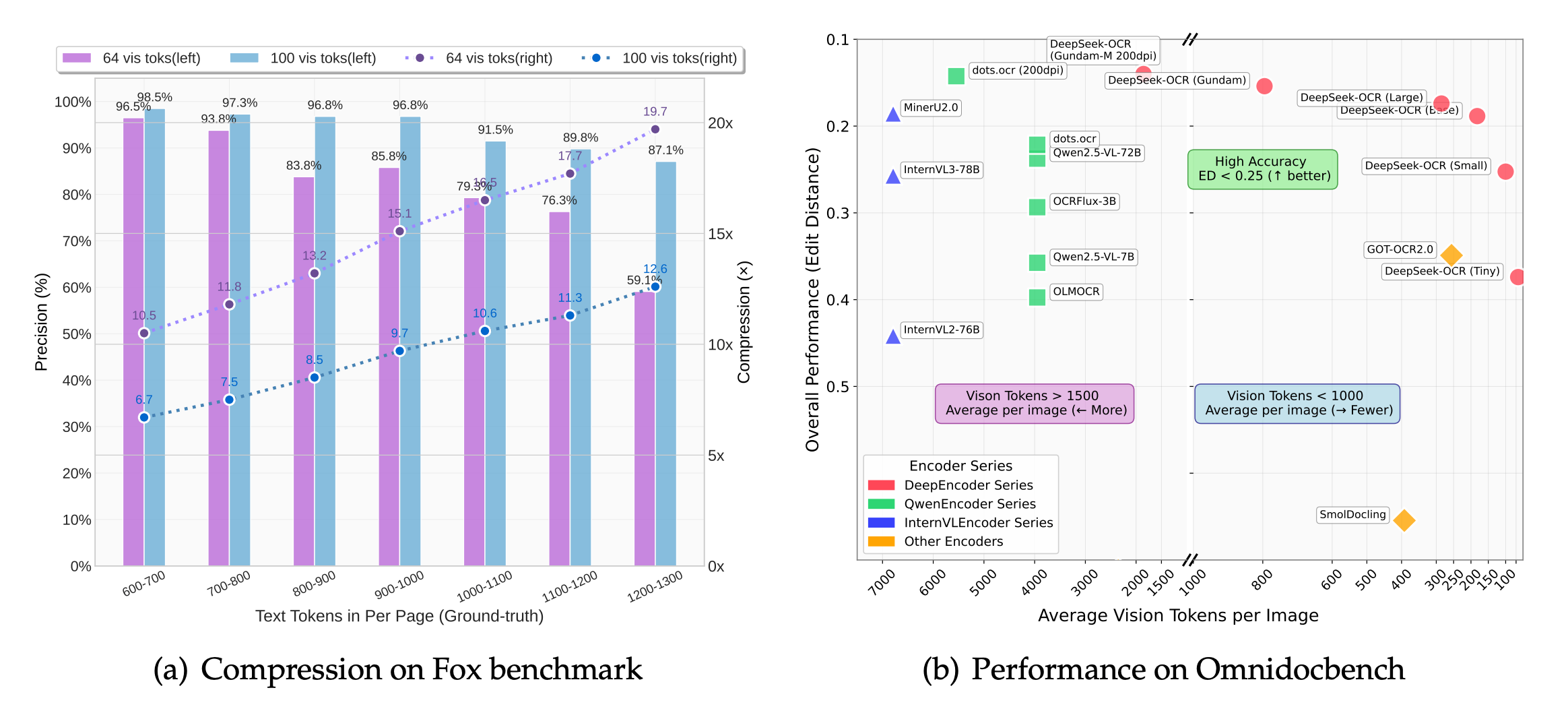
DeepSeek-OCR explores compressing long text contexts into visual representations using a novel vision encoder architecture (DeepEncoder) that achieves 10-20x compression ratios while maintaining high OCR accuracy.
Core compression insight: Treats images as an efficient compression medium for text. At 10x compression (1000 text tokens to 100 vision tokens), it achieves 97% OCR accuracy. Even at 20x compression, it maintains ~60% accuracy, demonstrating the feasibility of optical context compression for LLM memory mechanisms.
DeepEncoder architecture: Combines SAM-base (80M, window attention) and CLIP-large (300M, global attention) via 16x convolutional compressor. Sequential design ensures window attention processes high-token-count images while compression happens before dense global attention, maintaining low activation memory at high resolutions (1024x1024 produces only 256 vision tokens).
Multi-resolution flexibility: Supports native resolutions (Tiny: 64 tokens, Small: 100, Base: 256, Large: 400) and dynamic tiling (Gundam mode: n×100+256 tokens). Single model handles multiple compression ratios through simultaneous training on all resolution modes, enabling compression-quality trade-offs.
Production-ready performance: Surpasses GOT-OCR2.0 using only 100 vision tokens vs 256, outperforms MinerU2.0 (6000+ tokens/page) with under 800 tokens. Processes 200k+ pages/day on a single A100-40G GPU. Achieves SOTA on OmniDocBench among end-to-end models with the fewest vision tokens.
Extended capabilities: Beyond pure OCR, supports deep parsing (chart-to-HTML table, chemical formula-to-SMILES, geometry parsing), multilingual recognition (~100 languages), and general vision understanding through 70% OCR data + 20% general vision + 10% text-only training mix.
2. Continual Learning via Sparse Memory Finetuning
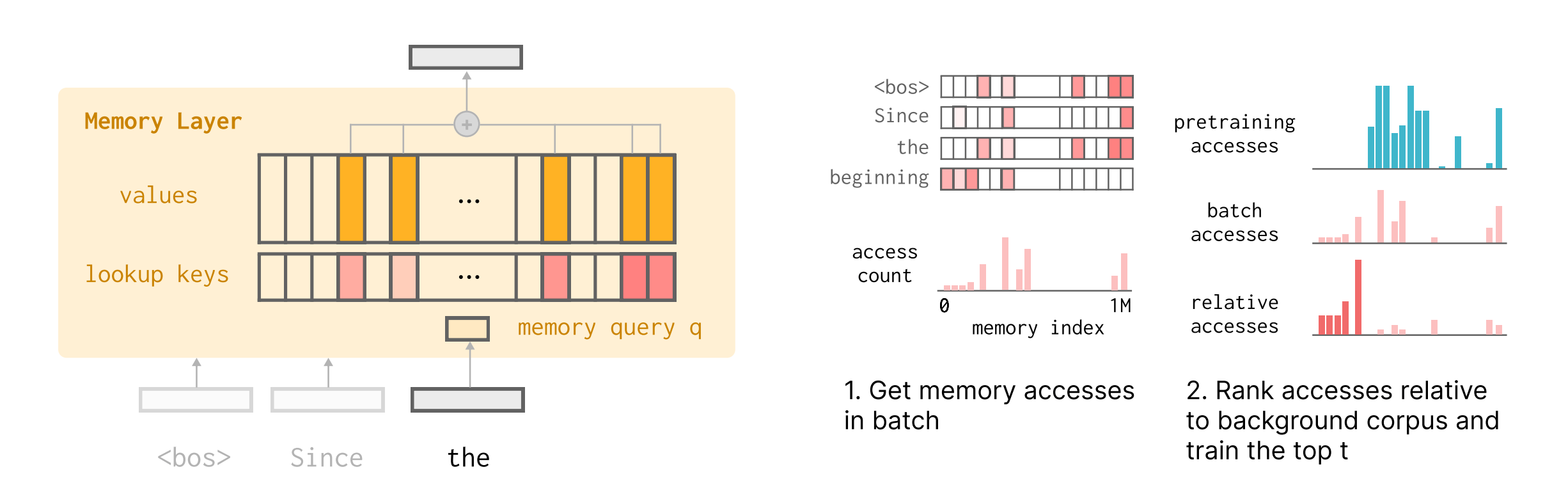
Meta AI researchers address catastrophic forgetting in language models through sparse memory finetuning, updating only memory slots most activated by new knowledge while achieving 89% less performance degradation than standard finetuning.
Core problem: Language models suffer catastrophic forgetting when updating on new information, losing previously acquired capabilities. Standard finetuning causes a 89% performance drop, and LoRA results in a 71% decline on held-out tasks, making continual learning impractical without expensive data replay strategies.
Memory layer architecture: Replaces feedforward layers with sparse parametric memory pools (1-10M slots) where each forward pass accesses only a small subset (e.g., 10k parameters). Provides balance between large overall capacity and minimal parameters per knowledge piece, enabling granular control over information storage.
TF-IDF ranking for sparsity: Identifies memory slots specific to new input by computing term frequency-inverse document frequency scores relative to background corpus (pretraining data). Updates only top-t slots (e.g., 500 out of 1M) that are highly accessed on the new batch but infrequently used in general knowledge, minimizing interference.
Empirical validation: On TriviaQA fact learning, sparse memory finetuning achieves only 11% performance drop on NaturalQuestions (vs 89% for full finetuning, 71% for LoRA) while learning equivalent new knowledge. Pareto dominates baselines across the learning-forgetting tradeoff frontier in both fact learning and document QA tasks.
Core set analysis: Facts are typically distributed across 100-500 memory indices forming “core sets” that align with entity boundaries. TF-IDF ranking successfully identifies these semantic content indices without access to test-time queries, enabling models to accumulate knowledge through continual experience.
3. When Models Manipulate Manifolds
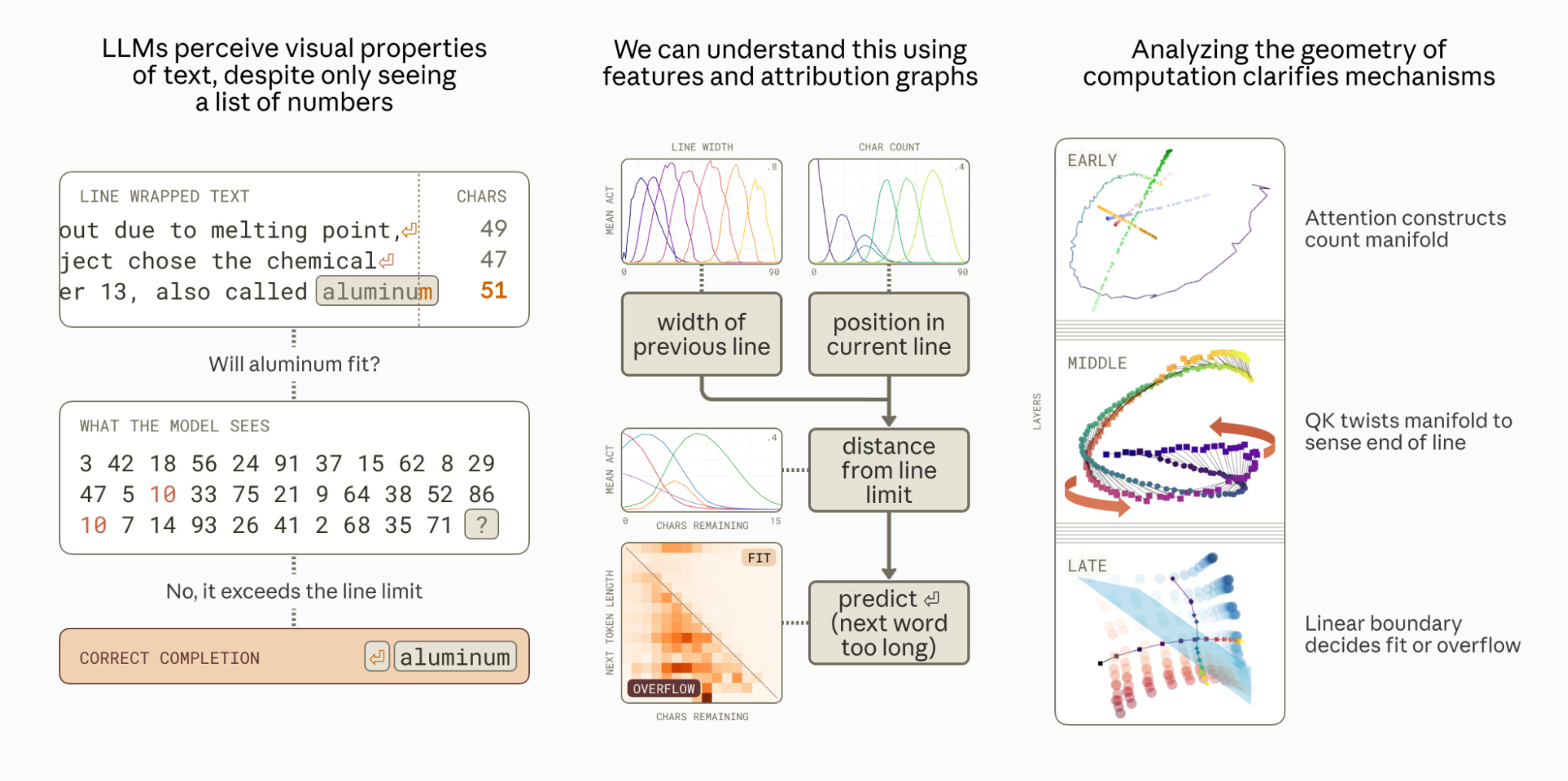
Anthropic researchers investigate how Claude 3.5 Haiku learns to predict line breaks in fixed-width text, revealing geometric representations analogous to biological place cells and boundary cells in biological brains.
Perceptual task in text space: Models must count characters in the current line, compare against line width constraints, and predict when to insert newlines. Language models receive only token sequences (integers), forcing them to learn visual/spatial reasoning from scratch without explicit position information.
Dual interpretation of representations: Character position is encoded both as discrete features (activation strength determines position) and as one-dimensional feature manifolds (angular movement on the manifold indicates position). Computation has dual views as discrete circuits or geometric transformations on the residual stream.
Biological parallels: Discovered learned position representations similar to mammalian place cells (encoding location in the environment) and boundary cells (detecting spatial boundaries). These emerge naturally from training on source code, chat logs, email archives, and judicial rulings with line width constraints.
Distributed counting algorithm: Model implements character counting through attention heads that track cumulative position, compare against learned boundary representations, and trigger newline predictions. Different layers handle character accumulation, boundary sensing, and final newline prediction sequentially.
Visual illusions in models: Just as humans experience visual illusions, models exhibit “perceptual” errors on edge cases. Provides a framework for understanding how abstract geometric structures in residual stream enable complex spatial reasoning tasks that humans perform subconsciously.
4. Bayesian Influence Functions for Hessian-Free Data Attribution
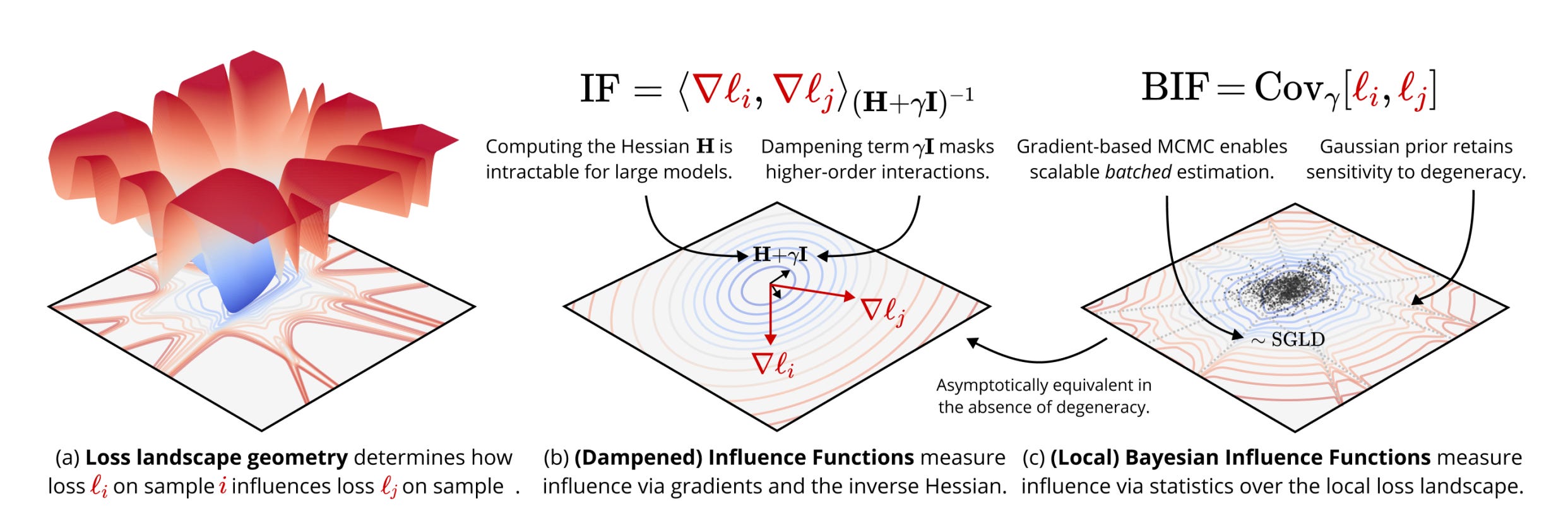
Classical influence functions struggle with deep neural networks due to non-invertible Hessians and high-dimensional parameter spaces. This work introduces the local Bayesian influence function (BIF), which replaces Hessian inversion with loss landscape statistics estimated via stochastic-gradient MCMC sampling.
Core innovation: BIF uses covariance estimation over the local posterior distribution rather than computing the problematic Hessian inverse. This distributional approach naturally handles degenerate loss landscapes in DNNs and reduces to classical influence functions for non-singular models.
SGLD-based estimation: Implements stochastic gradient Langevin dynamics to sample from a localized Bayesian posterior, computing covariances between training sample losses and query observables. The method is architecture-agnostic and scales to billions of parameters without structural approximations.
Computational trade-offs: No expensive fit phase like EK-FAC, but costs scale with the number of posterior draws. More efficient for fine-grained attribution (per-token influences computed in parallel). Classical methods excel when many queries amortize high setup costs.
Experimental validation: Achieves state-of-the-art on retraining experiments (Linear Datamodeling Score), matching or outperforming EK-FAC baseline. Shows 2 orders of magnitude faster evaluation on the largest Pythia models (2.8B parameters) while using the same GPU memory.
Interpretable per-token analysis: Captures semantic relationships in language models - correlations maximize for translations, alternate spellings, and synonyms. Reveals a hierarchical structure in vision models where similar categories show a positive influence.
5. Reasoning with Sampling
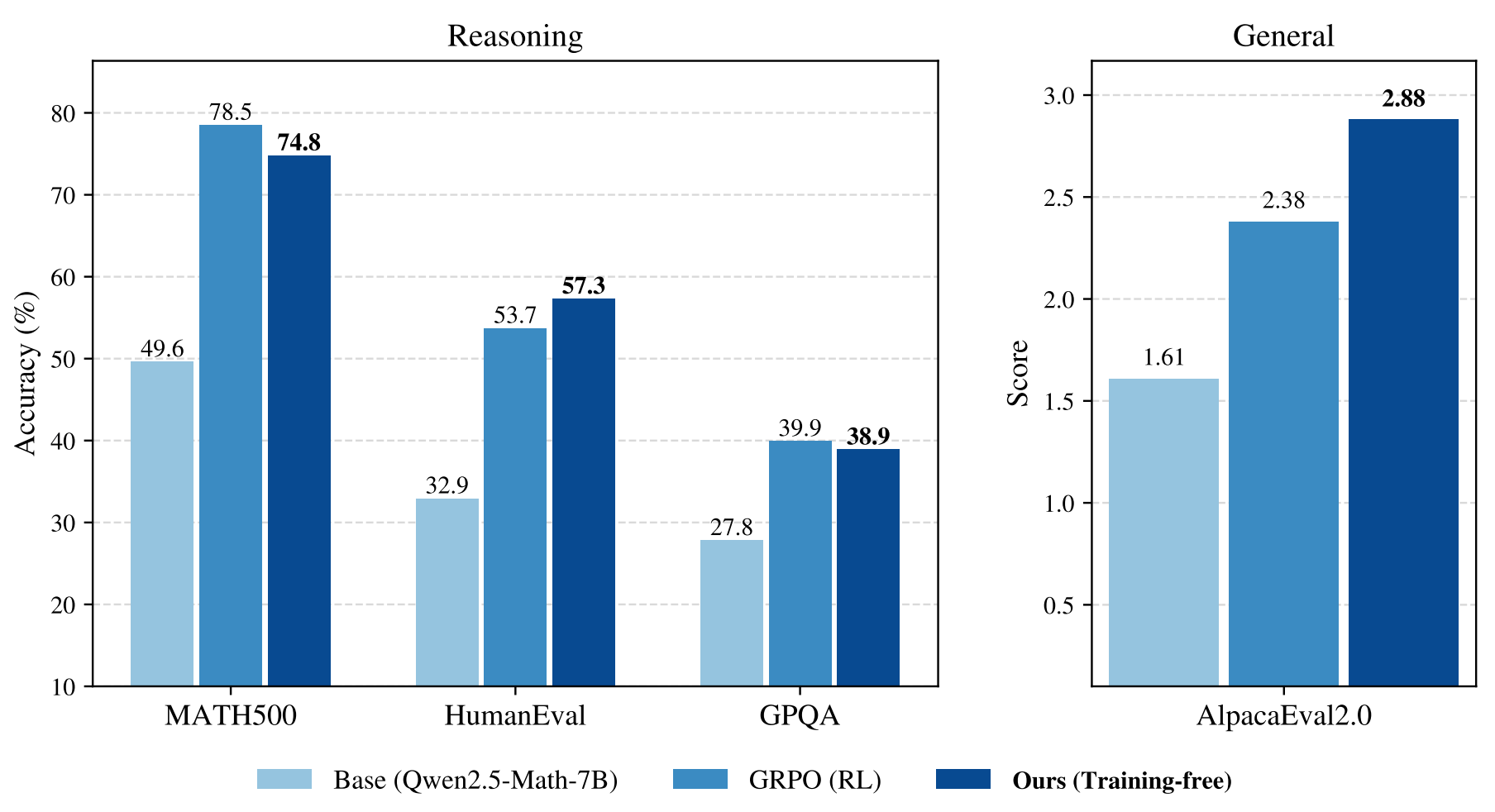
Base language models achieve reasoning performance matching or exceeding RL-posttraining through inference-time power distribution sampling, using MCMC techniques that require no training, datasets, or verifiers.
Core insight: RL-posttraining sharpens base model distributions rather than learning fundamentally new behaviors. Power distribution (p^α) sampling explicitly targets this sharpening by exponentiating base model likelihoods, upweighting high-probability sequences while maintaining diversity, unlike collapsed RL distributions.
Power vs low-temperature sampling: Low-temperature sampling exponentiates conditional next-token distributions (exponent of sums), while power sampling sums exponentiated future path likelihoods (sum of exponents). This crucial difference means power sampling accounts for future completions, upweighting tokens with few but high-likelihood paths over tokens with many low-likelihood completions.
MCMC implementation: Autoregressive algorithm progressively samples intermediate distributions using Metropolis-Hastings with random resampling. Uniformly selects an index, resamples from that point using the proposal LLM, and accepts/rejects based on the relative power distribution likelihoods. Block size B=192, α=4.0, inference cost ~8.84x standard sampling.
Empirical results: On Qwen2.5-Math-7B, achieves 74.8% on MATH500 (vs 78.5% GRPO), but outperforms on out-of-domain tasks - 57.3% HumanEval (vs 53.7% GRPO), 2.88 AlpacaEval score (vs 2.38 GRPO). Maintains generation diversity with superior pass@k performance at k>1, avoiding RL’s mode collapse.
Training-free advantage: No hyperparameter sweeps, curated datasets, or reward verifiers required. Broadly applicable beyond verifiable domains. Samples from the highest base model likelihood/confidence regions (similar to GRPO) while maintaining 679-token average response length, suggesting latent reasoning capabilities exist in base models.
6. Lookahead Routing for LLMs
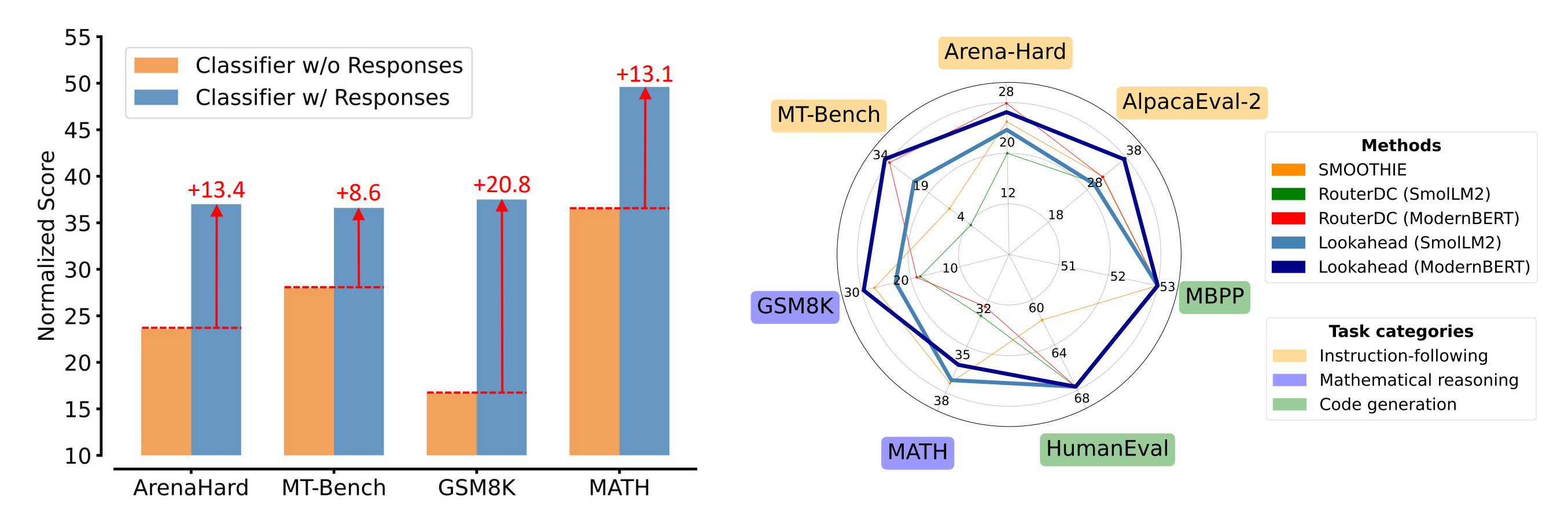
Lookahead is a response-aware LLM routing framework that predicts latent representations of potential model outputs to enable more informed routing decisions without full inference.
Core limitation of query-only routing: Traditional routers base decisions solely on input queries, missing critical information about actual response quality and semantic intent that emerges during generation. This leads to suboptimal routing on complex or ambiguous queries.
Dual implementation architecture: Sequence-level variant uses causal language models (CLM) that concatenate query with model identifier (MID) tokens, extracting hidden states at MID positions as response representations. Token-level variant uses masked language models (MLM) that jointly reconstruct all candidate responses via repeated MID token blocks, aggregating information through [CLS] token attention.
Curriculum masking strategy: MLM variant progressively masks from response end to start, increasing masking ratio linearly to 100% over the first 40% of training. This smooth transition from partial to full masking enables robust representations and better generalization than uniform random masking.
Joint training objective: Combines routing loss (binary cross-entropy on model selection) with response reconstruction loss (next-token prediction for CLM, masked token recovery for MLM). Auxiliary response modeling improves sample efficiency by 6.3x and captures richer semantic information via higher mutual information with oracle responses.
Performance: Achieves 7.7% average normalized score gain over SOTA RouterDC across 7 benchmarks (AlpacaEval-2, Arena-Hard, MT-Bench, GSM8K, MATH, HumanEval, MBPP). MLM variant excels on open-ended instruction-following tasks where joint semantic-space encoding enables fine-grained cross-model comparisons. Routes nearly 100% of code queries to the specialized Qwen2.5-Coder model, demonstrating strong specialization awareness.
7. Ring-1T
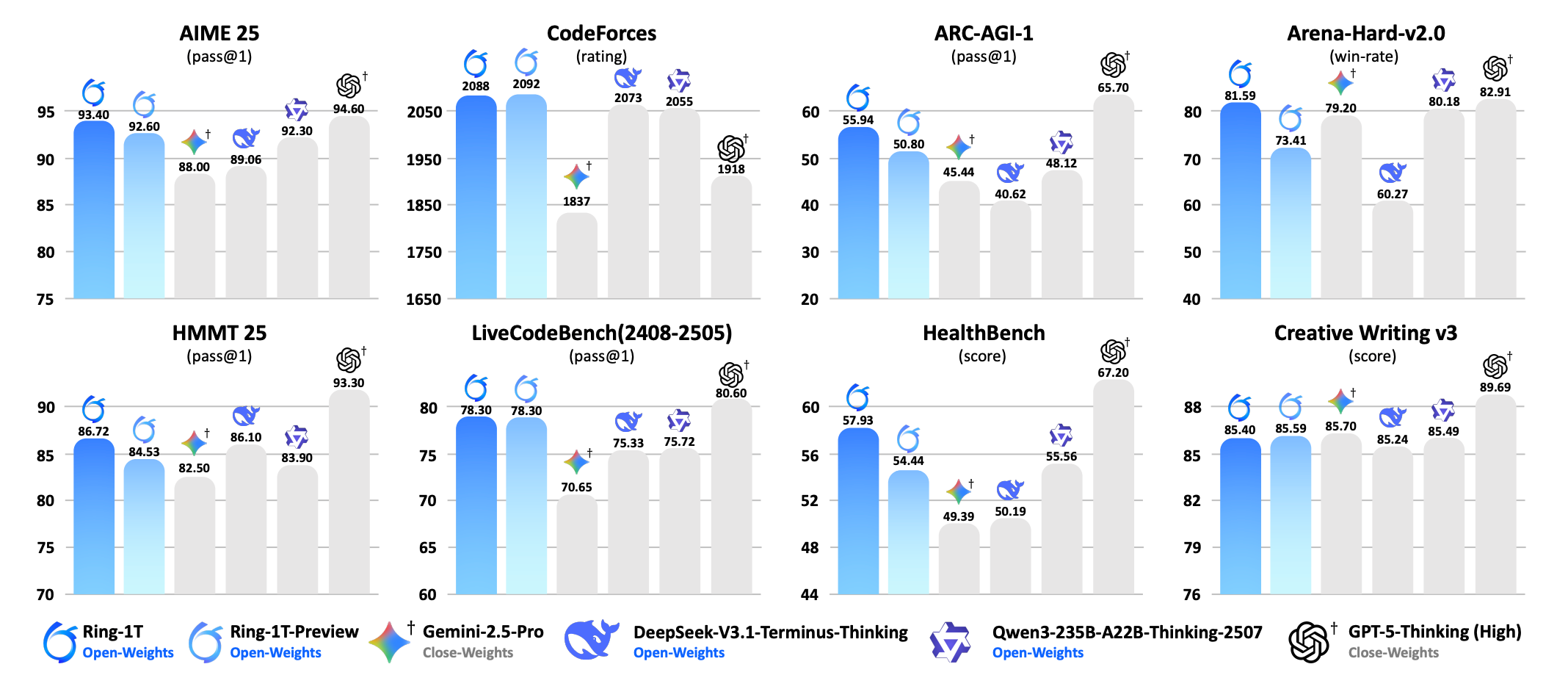
Ring-1T is the first open-source thinking model with 1 trillion parameters (~50B active per token), achieving breakthrough results through three innovations for trillion-scale RL training.
Benchmark performance: 93.4 on AIME-2025 (top open-weights), 86.72 on HMMT-2025, 2088 CodeForces rating (highest overall), and IMO-2025 silver medal via pure natural language reasoning.
IcePop fixes training-inference misalignment: Using separate training/inference engines causes probability discrepancies that compound in MoE models. IcePop applies token-level gradient calibration within bounds (α, β) and masks excessive-deviation tokens. Only 1-2‰ need clipping, maintaining stability.
C3PO++ speeds rollouts: Budget-controlled partitioning cuts generation at a token limit, preventing idle resources. Completed trajectories move to training; unfinished ones buffer and resume. Delivers 2.5× rollout speedup and 1.5× end-to-end speedup.
ASystem infrastructure: Hybrid Runtime (unified training-inference), AMem (GPU memory management), AState (sub-second weight sync), ASandbox (100ms startup). SingleController + SPMD architecture avoids data flow bottlenecks.
Training pipeline: Long-CoT SFT on multi-domain data (Math 46%, STEM 26%, Code 20%), Reasoning RL with verifiable rewards, General RL for alignment and safety.
8. ColorAgent
ColorAgent is a mobile OS agent combining step-wise RL and self-evolving training with a multi-agent framework for personalized user engagement. It achieves 77.2% success on AndroidWorld and 50.7% on AndroidLab (SOTA among open models), while scoring 58.66% on MobileIAR for personalized intent alignment and 68.98% on VeriOS-Bench for trustworthiness.
9. Prompt-MII
CMU researchers propose Prompt-MII, an RL framework that meta-learns instruction induction across 3,000+ HuggingFace datasets, achieving 4-9 F1 point improvements on 90 unseen tasks while requiring 3-13x fewer tokens than in-context learning. Unlike APE (2000 LLM calls) and GEPA (150 calls), it generates compact instructions in a single forward pass and is training-free at test time.
10. Enterprise Deep Research
Salesforce AI researchers present EDR, a transparent multi-agent framework for enterprise deep research with human-in-the-loop steering via todo-driven task management and steerable context engineering. It achieves SOTA on DeepResearch Bench (49.86), 71.57% win rate on DeepConsult, and 68.5% on ResearchQA while consuming 4x fewer tokens than LangChain’s open deep research.
This roundup highlights how cutting-edge AI research is rapidly tackling efficiency, reasoning, and continual learning, revealing practical pathways for deploying models that are both powerful and resource-conscious.