
🥇Top AI Papers of the Week
The Top AI Papers of the Week (September 22-28)
1. ARE
Metal SuperIntelligence Labs presents a research platform and benchmark for building and stress-testing agent systems in realistic, time-driven environments. The paper introduces a modular simulator (ARE) and a mobile-style benchmark (Gaia2) that emphasize asynchronous events, verification of write actions, and multi-agent coordination in noisy, dynamic settings.
Platform highlights: ARE models environments as apps, events, notifications, and scenarios, with time that keeps moving even while the agent thinks. A DAG scheduler governs dependencies, and agents interact via tools and an async notification queue.
Gaia2 benchmark: 1,120 verifiable scenarios in a smartphone-like environment with 101 tools across apps such as Email, Chats, Calendar, Shopping. Scenarios target six capabilities: Search, Execution, Adaptability, Time, Ambiguity, and Agent-to-Agent.
Verifier design: evaluation compares an agent’s sequence of write actions to oracle write actions, mixing hard checks for arguments like IDs with soft LLM judging for content. It validates causality and timing, and runs turn-by-turn for multi-turn scenarios.
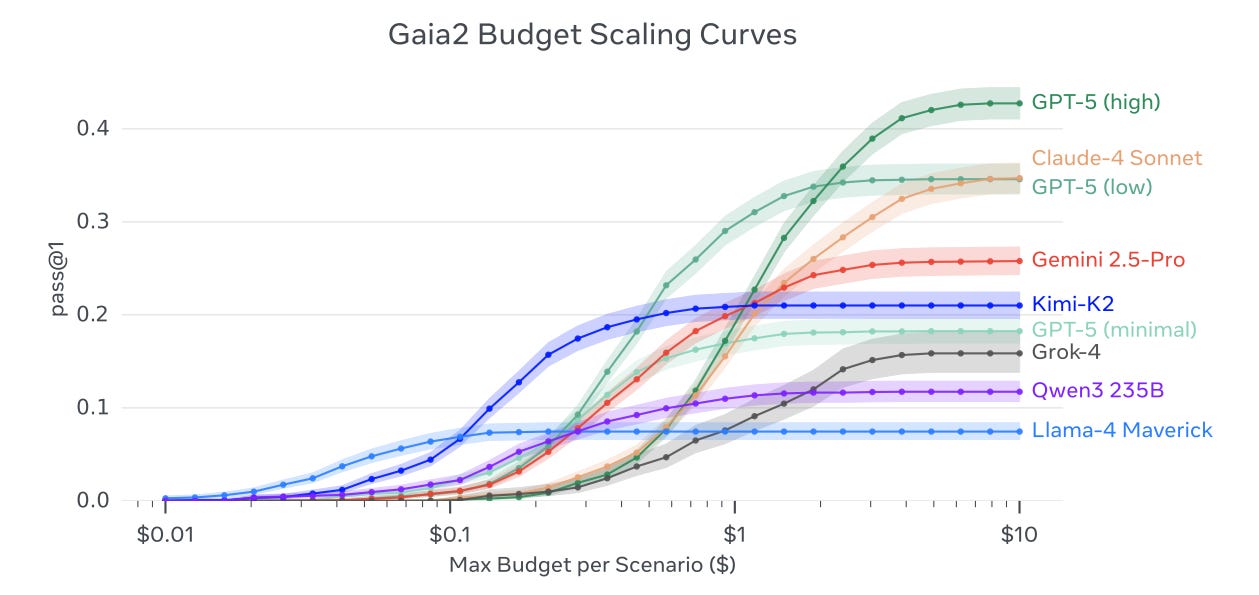
Key results and tradeoffs: no single model dominates across capabilities, and budget scaling curves plateau. The chart on page 1 shows pass@1 vs max budget.
Time and collaboration: timing pressure exposes an inverse scaling effect where heavy-reasoning policies score well elsewhere but miss time-critical windows; instant mode narrows this gap. Agent-to-Agent settings help lighter models through sub-goal delegation, with mixed gains for strongest systems. A GUI supports event-graph inspection, trace replay, and zero-code scenario authoring.
2. ATOKEN
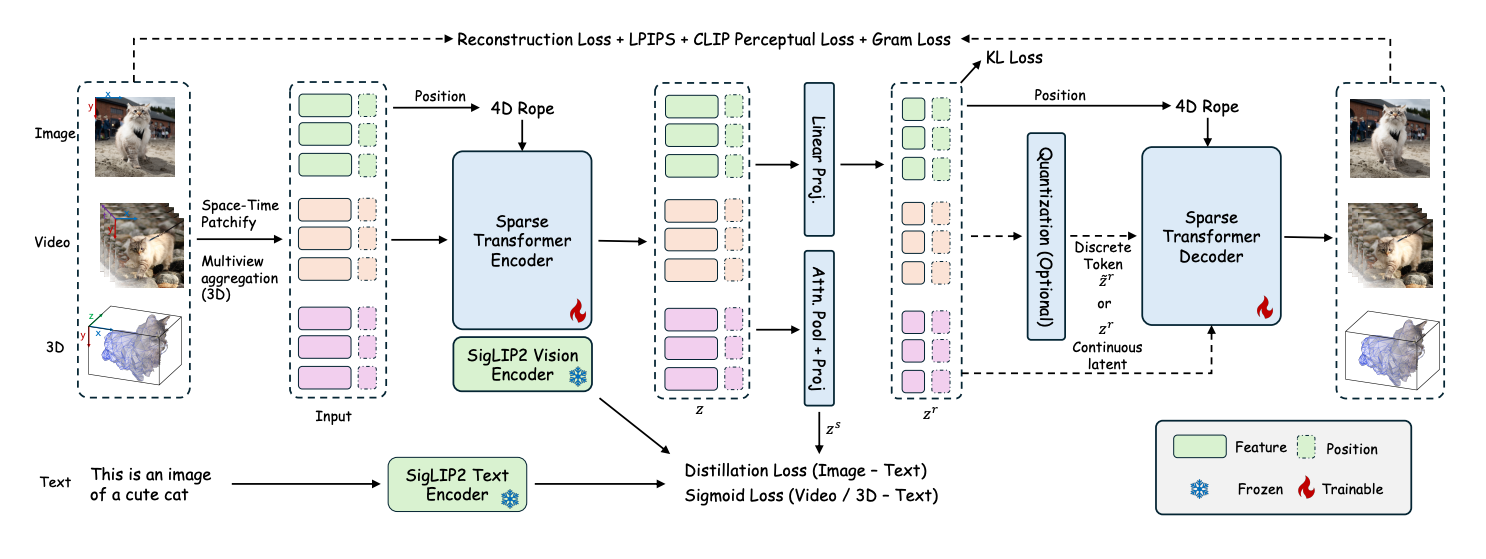
ATOKEN introduces a single transformer tokenizer that works for images, videos, and 3D assets. It encodes all inputs into a shared sparse 4D latent space with 4D RoPE, trains without adversarial losses, and supports both continuous and discrete tokens. The paper reports strong reconstruction quality and solid semantic alignment, enabling both generation and understanding across modalities.
One latent space for 2D, video, and 3D. Inputs are patchified into sparse (t, x, y, z) features, so images are 2D slices, videos add time, and 3D uses surface voxels aggregated from multiview renders.
Pure Transformer with 4D RoPE and native resolution. The encoder extends a SigLIP2 vision tower to space–time blocks and adds 4D rotary positions, while the decoder mirrors the transformer to reconstruct pixels or 3D Gaussians. Native resolution and KV-cached temporal tiling speed video inference.
Adversarial-free training that targets texture statistics. Instead of GANs, the loss mixes L1, LPIPS, CLIP perceptual, and a Gram-matrix term, motivated by an rFID decomposition showing covariance dominates error.
Progressive curriculum across modalities. Four stages grow capability: image recon, add video, add 3D, then optional FSQ quantization.
Results across the board. With continuous latents, ATOKEN reports 0.21 rFID and 82.2% ImageNet zero-shot accuracy for images, 36.07 PSNR and 3.01 rFVD for video, and 28.28 PSNR with 90.9% 3D classification on Toys4k. Discrete FSQ tokens remain competitive while enabling AR generation and image-to-3D.
3. Code World Model
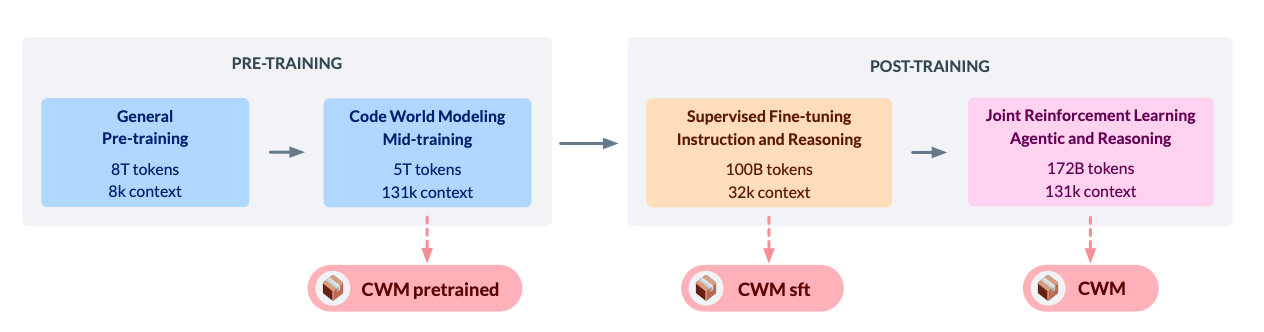
Meta FAIR releases CWM, a 32B open-weights coder trained to model code execution and to act inside containers. It mid-trains on Python interpreter traces and agentic Docker trajectories, then upgrades with multi-turn RL across SWE, coding, and math. CWM is both a strong coder and a testbed for world-model-style reasoning in software environments.
Execution-aware training recipe: Pretrain 8T tokens, then mid-train 5T on Python execution traces and ForagerAgent trajectories collected in containerized repos, followed by SFT (100B) and joint multi-task RL with a GRPO-style algorithm and asynchronous rollouts. Results include 120M traced functions, ~70k repo-level traces, and 3M agentic trajectories.
Model + context scaling: Dense 32B decoder with alternating local/global sliding-window attention and 131k max context. Scaled RoPE, GQA, FP8 training, and long-context bucketization are used to keep throughput sane. Inference can fit on a single 80 GB H100 with quantization.
Agentic RL design for SWE: The agent works inside a repo sandbox with a minimal toolset (bash, edit, create, submit), runs tests, builds patches with
git diff, and is rewarded by hidden tests plus patch-similarity shaping. Self-bootstrapped traces improve format adherence before RL.Performance highlights: On SWE-bench Verified, 53.9% base pass@1 and 65.8% with test-time scaling (best@k); chart on page 3 shows CWM competitive with much larger or closed models. Also LCB-v5 68.6, Math-500 96.6, AIME-24 76.0, CruxEval-Output 94.3.
Why it matters for AI devs: CWM exposes trace-prediction tokens to simulate Python execution in prompts, enabling grounded reasoning, neural-debugger workflows, and trace-guided code synthesis. Ablations show execution traces boost CruxEval, and ForagerAgent boosts agentic NLLs and SWE pass@1.
4. Teaching LLMs to Plan
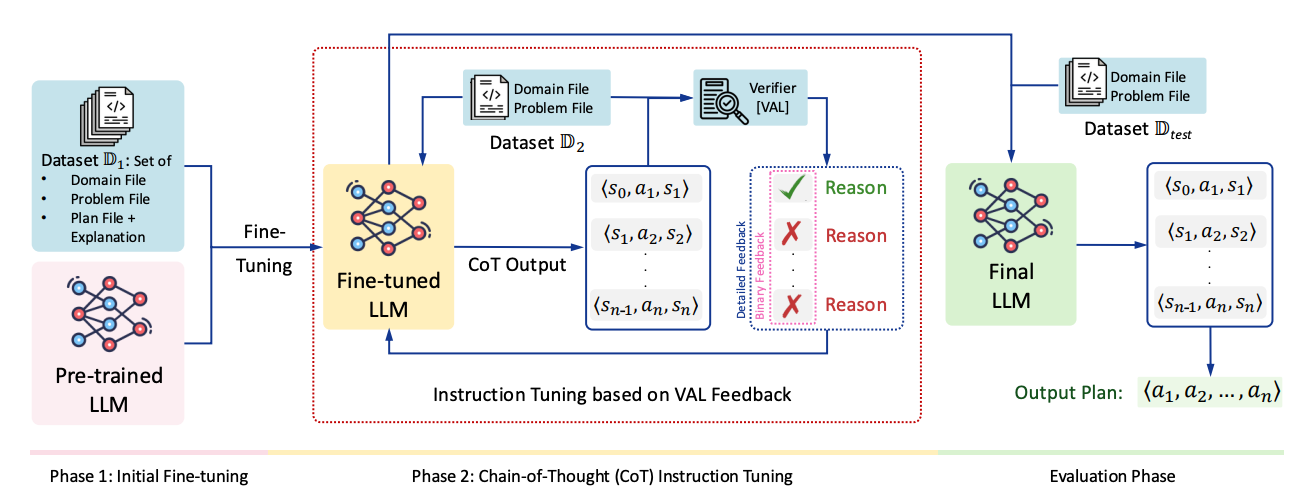
A training recipe that teaches LLMs to plan in Planning Domain Definition Language (PDDL) by making them write explicit state–action–state chains and checking each step with an external verifier (VAL). The result: big jumps in plan validity on PlanBench domains, especially when feedback explains why an action failed rather than just saying it failed.
Method in a nutshell: Two stages: (1) instruction tuning on correct and intentionally broken plans with explanations of preconditions and effects, then (2) CoT instruction tuning, where the model outputs ⟨s₀,a₁,s₁⟩… chains that VAL validates step-by-step. Training alternates between optimizing the reasoning chains and the final plan success.
Why it works: The verifier enforces logical coherence at each step, so the model learns to check preconditions, apply effects, and preserve invariants rather than pattern-match. This reduces unfaithful or hand-wavy CoT because every transition is externally validated.
Results: With Llama-3, detailed feedback and 15 iterations reach 94% plan validity on Blocksworld, 79% on Logistics, and 64% on Mystery Blocksworld. GPT-4 shows similar trends, peaking at 91%, 78%, and 59% respectively. Absolute improvements vs. baselines are large, e.g., +66% on some settings.
Feedback matters: Detailed feedback (which precondition failed or which effect was misapplied) consistently beats binary valid/invalid and benefits more from extra iterations (η from 10 to 15).
Scope and limits: Trained and tested on three PlanBench domains; performance drops on the obfuscated-predicate variant (Mystery Blocksworld), highlighting harder generalization. The method targets satisficing plans, not optimality, and currently assumes a PDDL subset without duratives or conditionals.
5. LLM-JEPA
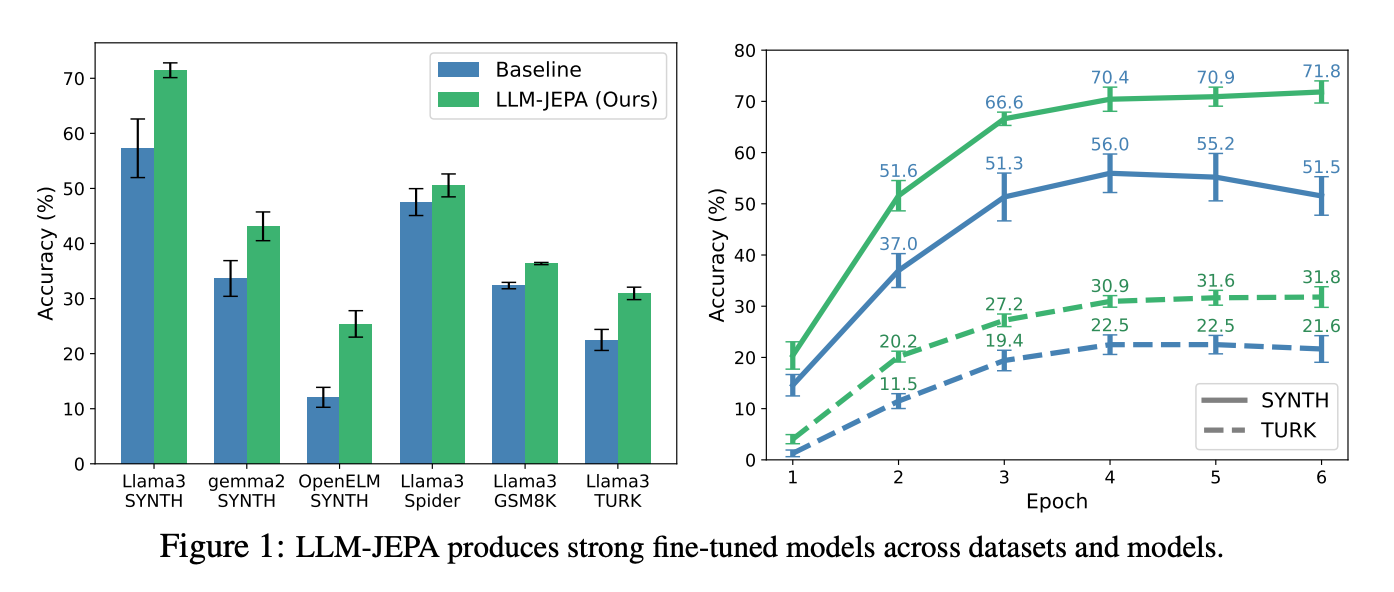
A JEPA-style training objective is adapted to LLMs by treating paired views of the same underlying content (for example, text and code) as prediction targets in embedding space, added on top of the usual next-token loss. The result consistently improves fine-tuning and shows promising pretraining gains, while being more resistant to overfitting.
Idea in one line: Keep the standard next-token objective and add a JEPA term that predicts the embedding of one view from another using tied LLM weights with special predictor tokens k, optimized with a cosine metric and weight λ. This preserves generation while improving abstraction.
Why it helps: Minimizing next-token loss alone does not reduce the JEPA prediction error; adding the JEPA term closes this gap and explains the accuracy lift.
Main results: Across Llama, Gemma, OpenELM and OLMo, LLM-JEPA improves exact-match accuracy on NL-RX (SYNTH and TURK), GSM8K, and Spider.
Representation effects: t-SNE plots show clearer structure when using LLM-JEPA, and a near-linear mapping from Enc(Text) to Enc(Code) is supported by low regression error and compressed singular values.
Pretraining signal and costs: Adding JEPA during pretraining improves downstream sentiment classification after standard fine-tuning, while keeping generative quality. Current limitation is extra compute from separate forward passes for each view, plus nontrivial hyperparameter sweeps over k and λ.
6. ARK-V1
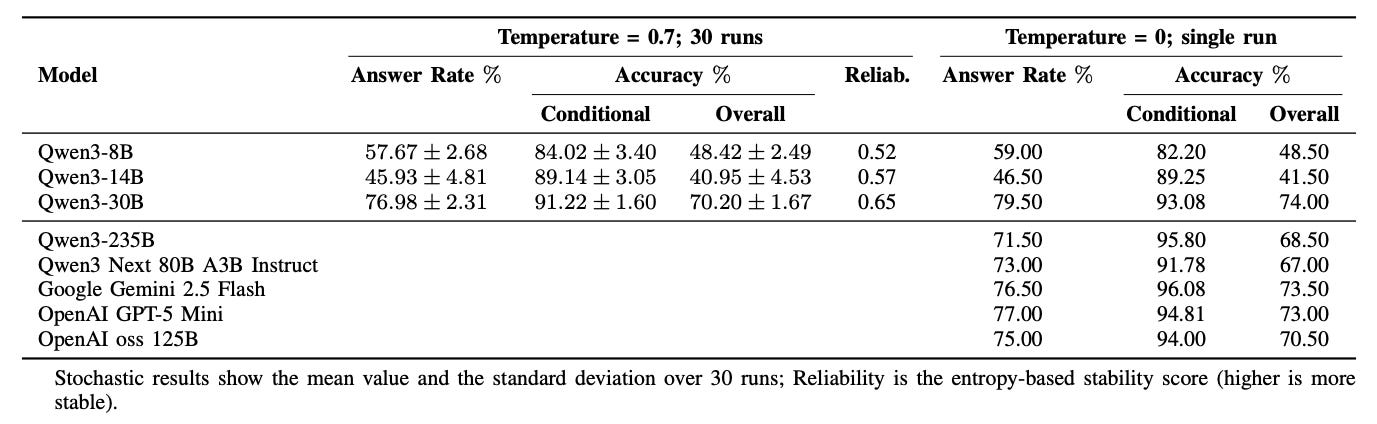
ARK-V1 is a lightweight agent that helps language models answer questions by actively walking through a knowledge graph instead of relying only on memorized text. This is especially useful for long-tail entities (less common stuff) where the model’s pretraining knowledge falls short.
How it works – The agent loops through a simple cycle: pick a starting entity, choose a relation, fetch matching graph triples, write a short reasoning step, and repeat until it’s ready to give an answer. Think of it like a mini search agent that explains its hops along the way.
The test – They used the CoLoTa dataset, which purposely asks questions about uncommon entities where you need both KG facts and commonsense (e.g., comparing populations of obscure towns). Metrics include how often the agent answers, how accurate it is when it does, and how consistent it is across runs.
Performance – ARK-V1 beats plain Chain-of-Thought prompting. With mid-scale models like Qwen3-30B, it answered ~77% of queries with ~91% accuracy on those, yielding ~70% overall. Larger backbones (Qwen3-235B, Gemini 2.5 Flash, GPT-5 Mini) hit ~70–74% overall with 94%+ conditional accuracy.
Weak spots – It struggles when (1) questions are ambiguous, (2) the KG contains conflicting triples, or (3) the KG lacks the needed commonsense, making the agent trust the graph too much.
Future directions – Current prompting is simple and traversal can be wasteful. Next steps include smarter prompts, efficiency tweaks, and applying the agent to specialized graphs like robotics scene graphs or enterprise data.
7. Language Models that Think, Chat Better

A simple recipe, RL with Model-rewarded Thinking, makes small open models “plan first, answer second” on regular chat prompts and trains them with online RL against a preference reward. On Llama-3.1-8B and Qwen-2.5-7B, this consistently beats standard RLHF on chat, creative writing, and general knowledge, with the best 8B model topping some frontier systems on WildBench and AlpacaEval2.
What’s new: Instead of rule-verifiable rewards (math, code), RLMT uses long chain-of-thought on diverse real-world prompts plus a reward model (Skywork) to score outputs, trained with online RL (GRPO, PPO, DPO).
Setup: Warm-start with small SFT on teacher-generated think→respond traces, then optimize with GRPO on ~7.5k WildChat-IF prompts. A “Zero” variant skips SFT and still works by prompting base models to emit think tags before answers.
Results at a glance: RLMT lifts chat scores by roughly 3–8 points over matched RLHF baselines. Table 1 reports Llama-3.1-8B-Instruct-RLMT at 50.4 (WildBench), 58.7 (AlpacaEval2), 22.9 (ArenaHardV2), and 84.3 (CreativeWritingV3), outperforming much larger open models and beating GPT-4o on WildBench.
Base models without SFT: With GRPO, RLMT-Zero notably upgrades chat ability from weak baselines; Qwen-2.5-7B-RLMT-Zero surpasses its vendor Instruct model on average chat metrics.
Why it works (and what matters): Ablations show prompt mixture quality and reward-model strength are pivotal (WildChat-IF and Skywork-V2 win). Post-RL, models plan differently: fewer linear checklists, more constraint enumeration, theme grouping, and iterative refinement. CoT and responses lengthen over training.
8. Embodied AI: From LLMs to World Models
This paper surveys embodied AI through the lens of LLMs and World Models (WMs). It highlights how LLMs enable semantic reasoning and task decomposition, while WMs provide predictive, physics-grounded interaction, and argues for a joint MLLM-WM architecture to advance real-world embodied cognition and applications.
9. GDPval
GDPval is a new benchmark of 1,320 real-world tasks across 44 occupations in 9 major GDP sectors, graded by industry experts with a 220-task gold set. It shows frontier models improve roughly linearly and are nearing expert parity, with Claude Opus 4.1 preferred or tied 47.6% of the time, while GPT-5 leads in accuracy. Model-plus-human workflows can reduce time and cost, and adding reasoning effort and prompt scaffolding further raises scores, with an open gold set and automated grader available for researchers.
10. Automating the Search for Artificial Life with Foundation Models
ASAL uses vision-language foundation models to automatically search across ALife substrates for simulations that match prompts, sustain open-ended novelty, or maximize diversity, reducing manual trial-and-error. It discovers new Lenia and Boids life-forms and lifelike CAs with strong open-endedness, and leverages FM embeddings to quantify emergent behaviors in a substrate-agnostic way.
i like it
Great roundup! These papers show the frontier of AI, from multi-agent benchmarks (ARE) and multimodal tokenizers (ATOKEN) to execution-aware code models (CWM) and embodied AI. Perfect for anyone wanting to stay on top of emerging research trends.