
🥇Top AI Papers of the Week
The Top AI Papers of the Week (December 29 - January 4)
1. End-to-End Test-Time Training for Long Context
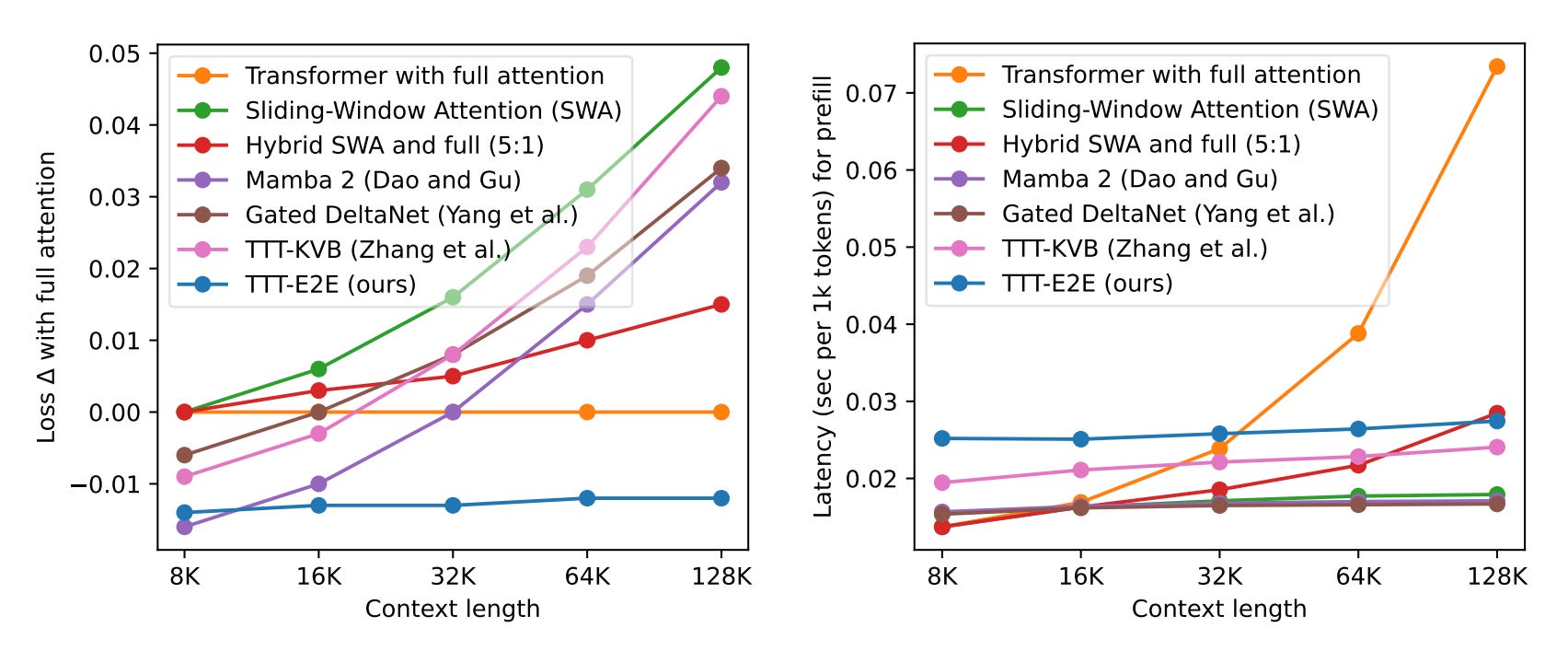
This paper reframes long-context language modeling as a continual learning problem rather than architecture design. TTT-E2E uses a standard Transformer with sliding-window attention that continues learning at test time via next-token prediction, compressing context into its weights rather than storing all key-value pairs.
Test-time training approach: The model learns at test time by predicting next tokens on the given context, compressing information into weights. This is combined with meta-learning at training time to prepare the model’s initialization for test-time learning.
End-to-end in two ways: The inner loop directly optimizes next-token prediction loss, while the outer loop optimizes the final loss after TTT via gradients of gradients. This contrasts with prior TTT methods and dynamic evaluation approaches.
Scaling with context length: For 3B models trained on 164B tokens, TTT-E2E scales with context length the same way as full attention Transformers, while alternatives like Mamba 2 and Gated DeltaNet do not maintain performance in longer contexts.
Efficient inference: Similar to RNNs, TTT-E2E has constant inference latency regardless of context length, making it 2.7x faster than full attention for 128K context on H100 while achieving comparable or better loss.
Message from the Editor

We are excited to announce our second cohort on Claude Code for Everyone. Learn how to leverage Claude Code to vibe code production-grade AI-powered apps.
Use coupon code EARLYBIRDCC2 for 20% today. Seats are limited!
2. Geometric Memory in Sequence Models
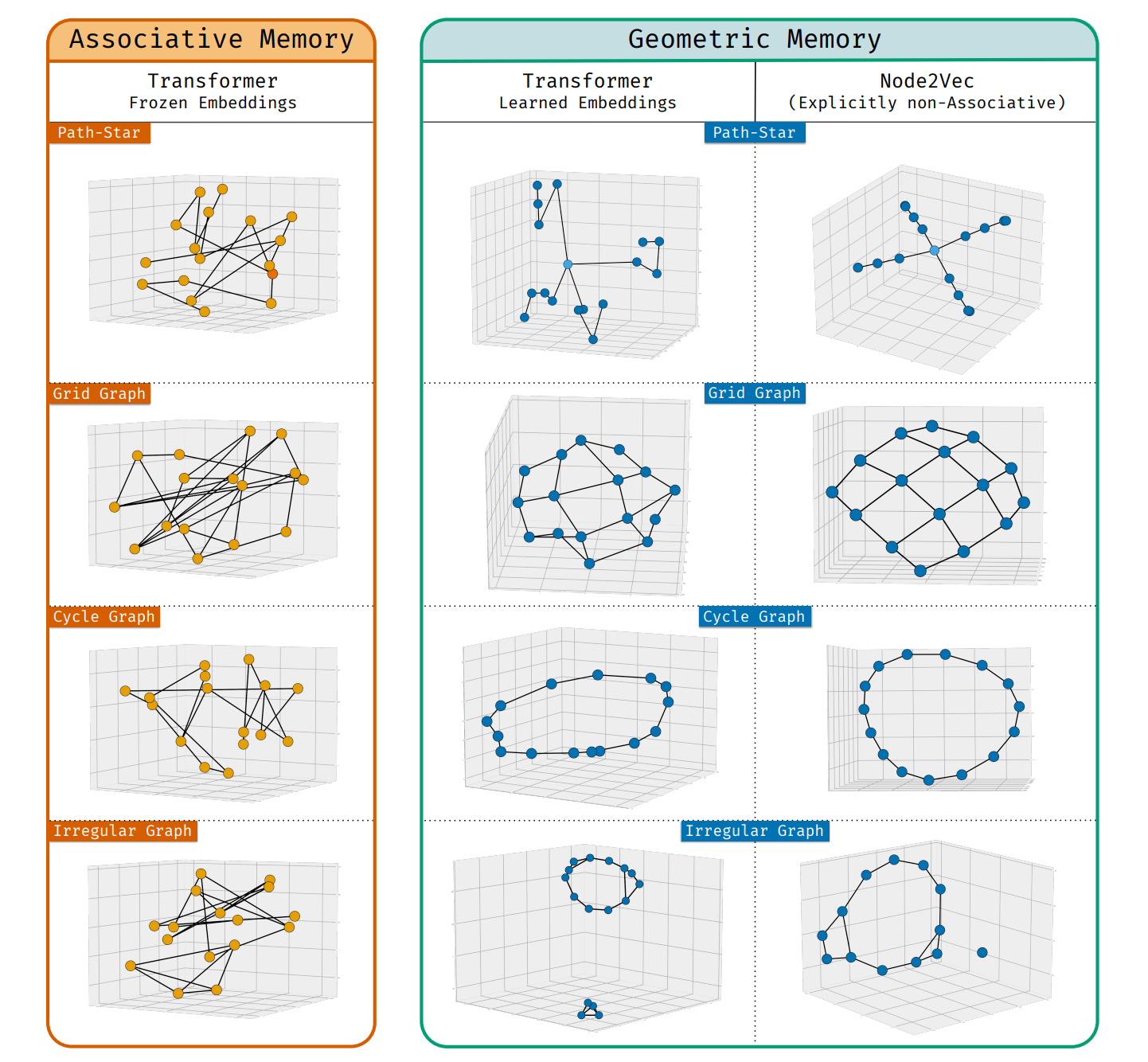
This paper identifies a dramatically different form of how deep sequence models store factual information called geometric memory, contrasting with the traditional associative memory view. Models synthesize embeddings encoding global relationships between all entities, even ones that never co-occur in training.
Two memory paradigms: Associative memory uses brute-force lookup of co-occurring entities with arbitrary embeddings. Geometric memory instead encodes global structure in carefully arranged embeddings where dot products capture multi-hop distances between entities.
Powerful reasoning transformation: Geometric memory transforms hard reasoning tasks involving multi-step composition into easy-to-learn 1-step navigation tasks. Models succeed at path-finding on massive graphs when memorizing edges in weights, despite being designed to fail.
Unexplained emergence: The geometry is learned even when it is more complex than brute-force lookup, without global supervision, rank constraints, or obvious architectural pressures. This creates a fundamental memorization puzzle.
Spectral bias explanation: By analyzing connections to Node2Vec, the researchers demonstrate that geometry stems from spectral bias arising naturally from cross-entropy loss minimization. Node2Vec models show more strongly geometric embeddings than Transformers, pointing to headroom for improvement.
3. Universal Reasoning Model
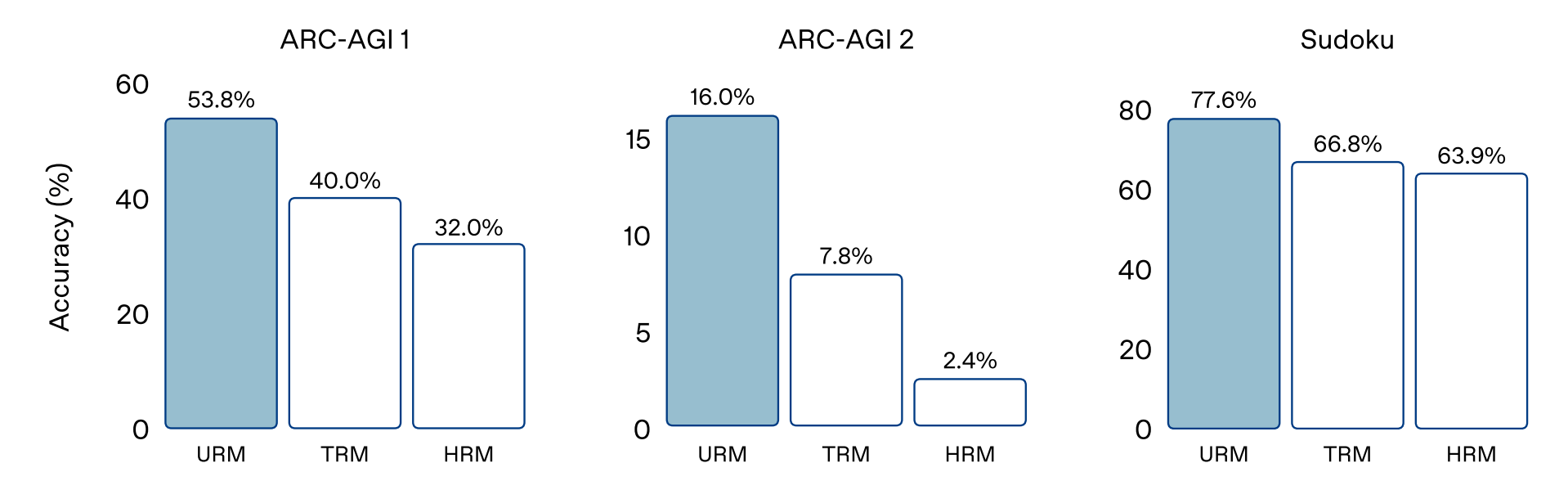
This paper investigates why universal transformers excel at complex reasoning tasks like ARC-AGI. The key finding: performance gains come primarily from recurrent inductive bias and strong nonlinear components rather than elaborate architectural designs.
Recurrent mechanism matters most: Through extensive ablation studies, the researchers show that reasoning capability beyond standard transformers comes from the recurrent mechanism of universal transformers, not from overly elaborate designs in prior work.
ConvSwiGLU enhancement: The Universal Reasoning Model (URM) augments the standard SwiGLU feed-forward block with depthwise short convolution, injecting local contextual interactions into the gating mechanism without increasing sequence-level complexity.
Truncated backpropagation: The approach uses truncated backpropagation through loops, enabling efficient training of the recurrent architecture while maintaining strong performance on reasoning tasks.
State-of-the-art ARC-AGI results: URM achieves 53.8% pass@1 on ARC-AGI 1 and 16.0% pass@1 on ARC-AGI 2, substantially outperforming prior UT-based models like TRM (40%) and HRM (32%) on ARC-AGI 1.
4. AI Agents for Coding in 2025
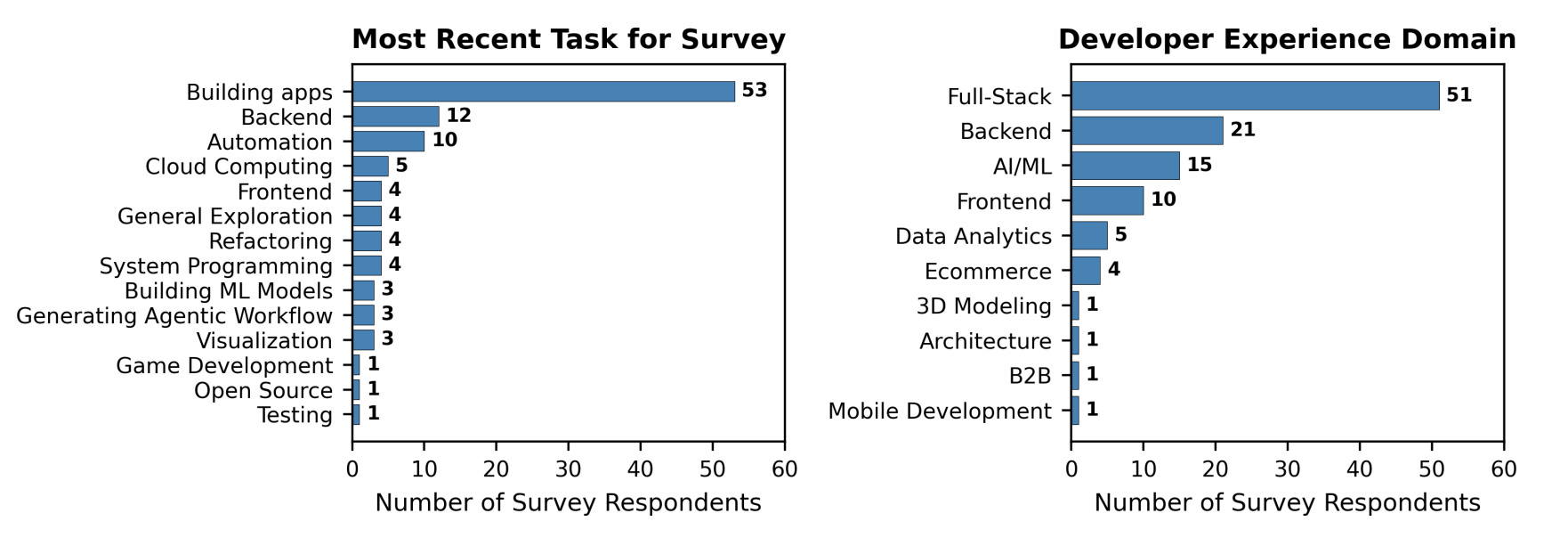
This study from UC San Diego and Cornell examines how experienced software developers (3+ years) actually use AI coding agents, through field observations (N=13) and surveys (N=99). The key finding: professional developers don’t “vibe code” - they carefully control agents through planning and supervision.
Control over vibing: Unlike the “vibe coding” trend, where developers trust AI without reviewing code, experienced professionals maintain careful oversight. They plan before implementing and validate all agentic outputs to ensure software quality.
Productivity with quality: Developers value agents as a productivity boost while still prioritizing software quality attributes. Some reported feeling their productivity increased tenfold, though they emphasized maintaining control over the process.
Task suitability: Agents perform well on well-described, straightforward tasks but struggle with complex tasks. The study found agents suitable for code generation, debugging, and boilerplate, but less effective for architectural decisions.
Positive sentiment with control: Developers generally enjoy using agents as long as they remain in control. A notable randomized trial found experienced maintainers were actually slowed by 19% when using AI, highlighting the importance of proper integration strategies.
5. Manifold-Constrained Hyper-Connections
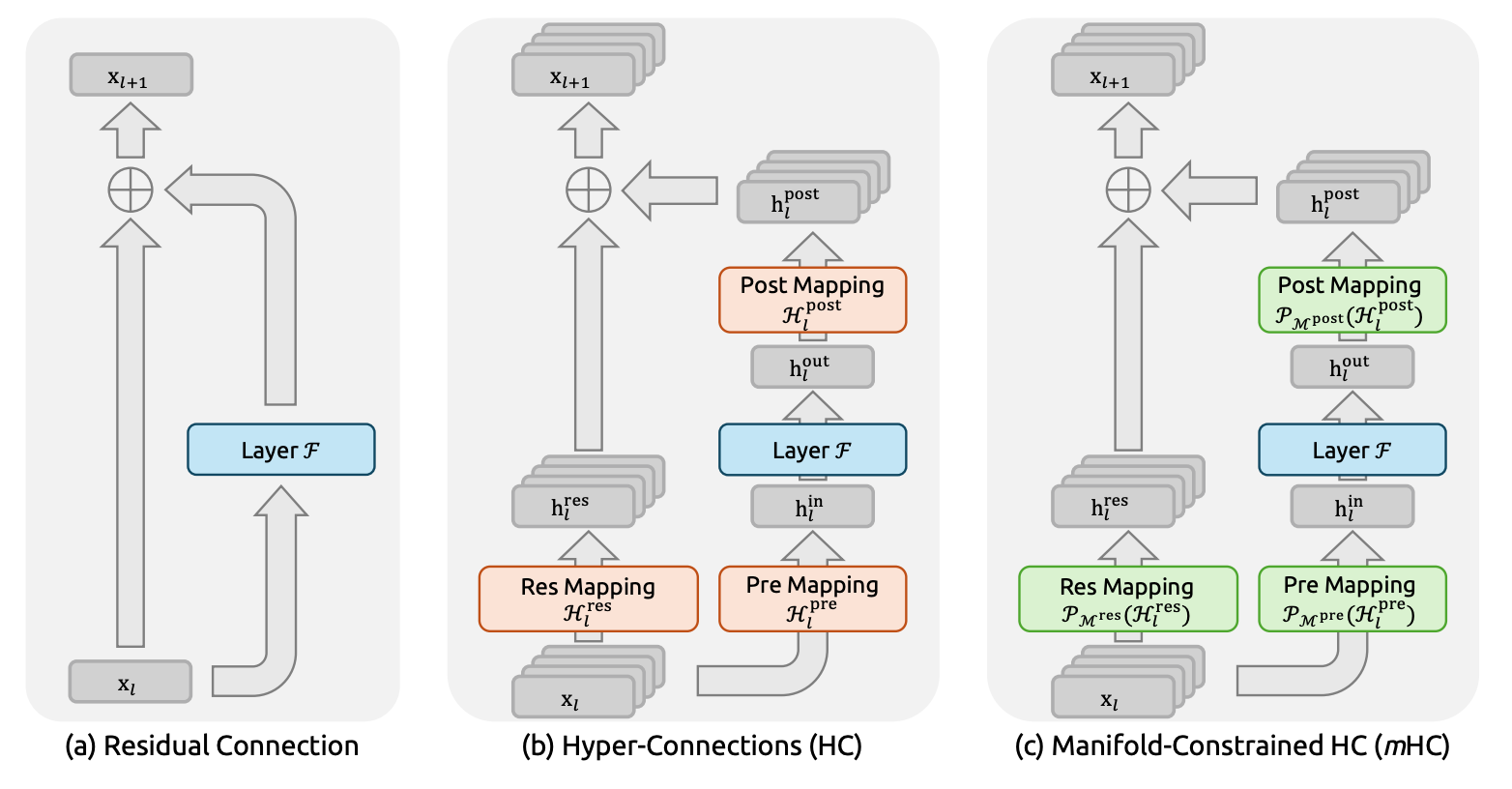
This DeepSeek paper proposes Manifold-Constrained Hyper-Connections (mHC), a framework that extends residual connections by expanding residual stream width while restoring training stability. The key insight: unconstrained Hyper-Connections compromise identity mapping, causing training instability at scale.
Identity mapping restoration: mHC projects residual connection matrices onto the Birkhoff polytope using the Sinkhorn-Knopp algorithm, constraining them to doubly stochastic matrices. This preserves the feature mean during propagation and prevents vanishing or exploding signals.
Stability at scale: Standard Hyper-Connections showed loss surges around 12k steps with gradient norm instability and Amax Gain Magnitude peaks of 3000. mHC maintains stable training by ensuring the composite mapping across layers preserves conservation properties.
Efficient infrastructure: The approach uses kernel fusion with TileLang, selective recomputing to reduce memory footprint, and overlapped communication within the DualPipe schedule. This introduces only 6.7% additional time overhead at expansion rate n=4.
Scalable performance: Experiments demonstrate mHC maintains the performance advantages of Hyper-Connections while enabling training at scale, offering a practical path for scaling via residual stream width rather than just model FLOPs or data size.
6. Spacing Effect for Generalization
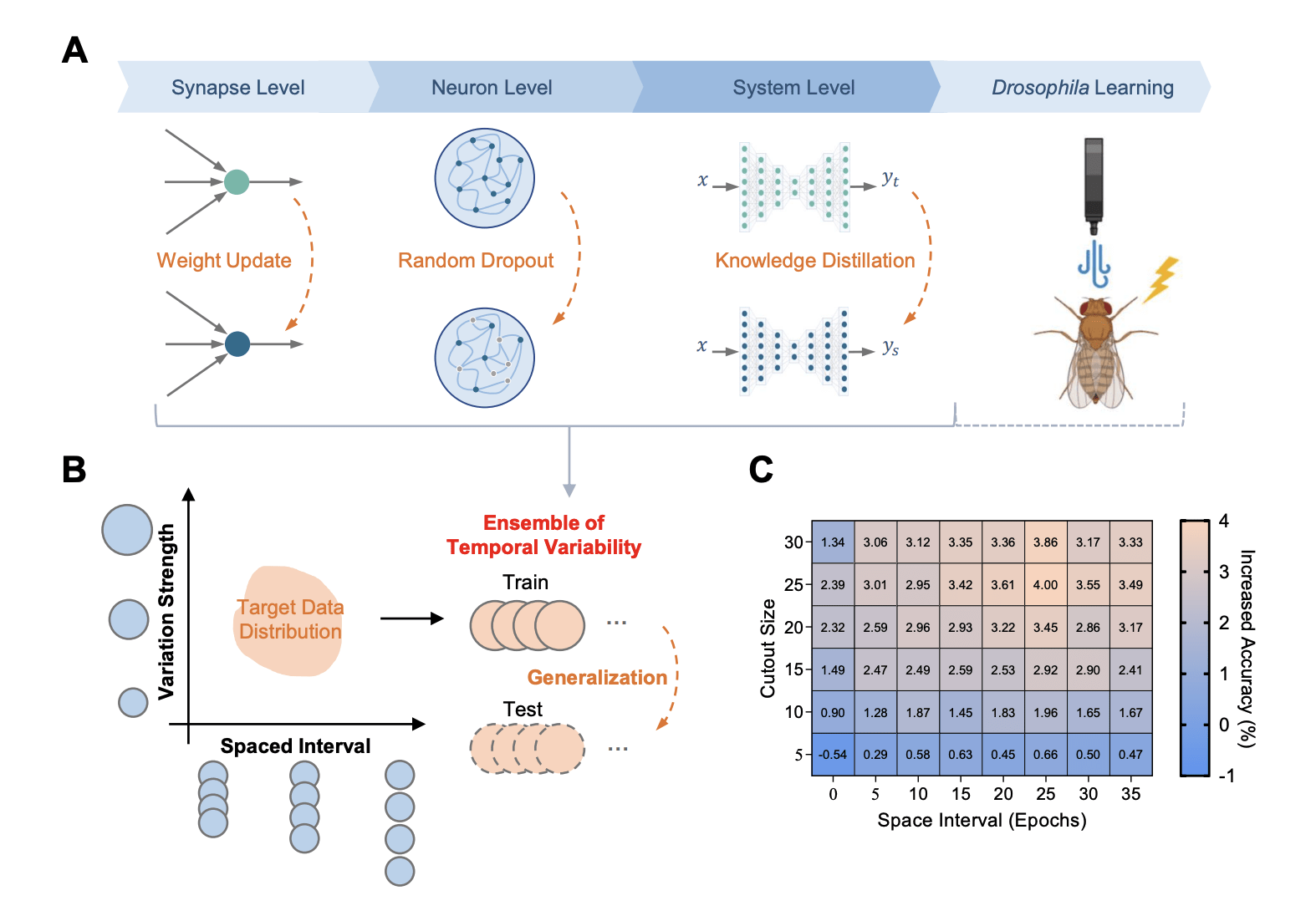
Researchers from Tsinghua University investigate how the spacing effect - a well-documented learning principle where spaced intervals between training improve retention - can enhance generalization in both biological and artificial neural networks.
Bio-inspired hypothesis: The spacing effect promotes integration of input and innate variations during learning, enabling better generalization to novel but related scenarios. The researchers test this by introducing bio-inspired spacing mechanisms into artificial neural networks.
Spaced dropout implementation: The approach implements structured dropout where probability varies periodically to introduce structured neuronal variability during training. Test accuracy follows a U-shaped trend, indicating optimal performance at intermediate variation strengths.
Cross-architecture validation: Performance gains from spaced dropout are demonstrated across different network architectures and benchmark datasets, showing the approach generalizes beyond specific model types.
Flatter loss landscapes: Theoretical and empirical analyses show that spacing effect benefits stem from convergence to flatter loss landscapes during stochastic gradient descent, resulting in better real-world performance and stronger resistance to noisy data.
7. SAGA

SAGA (Scientific Autonomous Goal-evolving Agent) introduces a framework for automating objective function design in AI-driven scientific discovery. Rather than optimizing fixed objectives specified by scientists, SAGA dynamically reformulates research goals throughout the discovery process to avoid reward hacking issues.
Bi-level architecture: SAGA employs an outer loop where LLM agents analyze optimization outcomes and propose refined objectives, while an inner loop performs solution optimization. This enables systematic exploration of objective trade-offs that remain invisible in traditional fixed-objective approaches.
Three automation modes: The framework offers co-pilot (human collaboration on analysis and planning), semi-pilot (human feedback to analyzer only), and autopilot (fully automated) modes for flexible human-AI interaction.
Diverse scientific applications: SAGA was validated across antibiotic design for K. pneumoniae, inorganic materials design (permanent magnets, superhard materials), functional DNA sequence design, and chemical process flowsheets.
Strong performance: In antibiotic design, SAGA achieved drug-like molecules with high predicted activity while baselines either failed to optimize activity or produced chemically invalid structures. For materials, SAGA found 15 novel stable structures within 200 DFT calculations, outperforming MatterGen. In DNA design, SAGA improved MPRA specificity by at least 48% over baselines.
8. Step-DeepResearch
Step-DeepResearch is a 32B parameter deep research agent that rivals OpenAI and Gemini DeepResearch through atomic capability training - decomposing research into planning, information gathering, cross-source verification, and report writing. Achieving 61.42 on Scale AI ResearchRubrics with a streamlined ReAct-style design, it outperforms larger models while being the most cost-effective deep research agent available.
9. MACI
This paper argues that LLMs are not fundamentally limited as pattern matchers - the real bottleneck is the lack of a System-2 coordination layer. The authors propose MACI, an architecture implementing three mechanisms: baiting (behavior-modulated debate), filtering (Socratic judging), and persistence (transactional memory) to enable goal-directed reasoning on top of LLM substrates.
10. AgentReuse
AgentReuse addresses latency bottlenecks in LLM-driven agents by caching and reusing plans for similar requests, observing that about 30% of agent requests are identical or similar. Using intent classification for semantic similarity rather than surface-level text comparison, the system achieves a 93% effective plan reuse rate and 93.12% latency reduction compared to systems without plan reuse.