
🥇Top AI Papers of the Week
The Top AI Papers of the Week (January 12-18)
1. Learning Latent Action World Models In The Wild
Meta AI researchers address learning world models from in-the-wild videos without requiring explicit action labels, expanding beyond simple robotics simulations and video games to real-world video data with diverse embodiments and uncontrolled conditions.
Latent action learning: The work demonstrates that continuous but constrained latent actions can capture the complexity of actions from in-the-wild videos, outperforming vector quantization approaches commonly used in prior work.
Cross-video transfer: Changes in the environment coming from agents, such as humans entering a room, can be transferred across different videos, indicating that the learned latent actions capture meaningful and generalizable environmental interactions.
Universal interface: Despite challenges from diverse embodiments across videos, the researchers train a controller that maps known actions to latent ones, enabling latent actions to serve as a universal interface for downstream planning tasks.
Comparable to action-conditioned baselines: The latent action approach achieves comparable performance to action-conditioned baselines on planning tasks, demonstrating practical viability without requiring explicit action labels during training.
Scaling to real-world data: The work represents progress toward scaling latent action models to realistic video data, addressing fundamental challenges in learning from diverse, uncontrolled video sources that lack action annotations.
2. Extending Context by Dropping Positional Embeddings
.")
DroPE introduces a method for extending a language model’s context window after pretraining without expensive long-context fine-tuning. The approach involves removing positional embeddings from a pretrained model and performing brief recalibration at the original context length.
Core insight: Positional embeddings serve as a “training-time scaffold” - beneficial during pretraining but detrimental for extrapolation. RoPE enables faster attention non-uniformity development during training, but becomes problematic at test time when sequences exceed training length.
The length generalization problem: Popular RoPE scaling methods preserve perplexity but essentially “crop” effective context, failing at retrieval tasks requiring long-range attention. DroPE addresses this by completely removing the positional scaffold after training.
Simple methodology: The approach is straightforward: train or obtain a pretrained RoPE-based model, remove positional embeddings post-pretraining, then recalibrate briefly using as little as 0.5-2% of the original pretraining budget.
Strong recovery: Models regain 95%+ in-context performance after less than 5B recalibration tokens. On needle-in-haystack tasks, DroPE substantially outperforms RoPE-scaling methods that fail at long-range retrieval.
Scalability and benchmarks: Validated on models up to 7B parameters trained on trillions of tokens. Improves base SmolLM scores by 10x on LongBench and enables zero-shot context extension to 2x training length without task-specific fine-tuning.
Message from the Editor

Excited to announce our new cohort-based training on Claude Code for Everyone. Learn how to leverage Claude Code features to vibecode production-grade AI-powered apps.
Seats are limited for this cohort. Grab your spot now.
3. Self-Evolving Search Agents Without Training Data
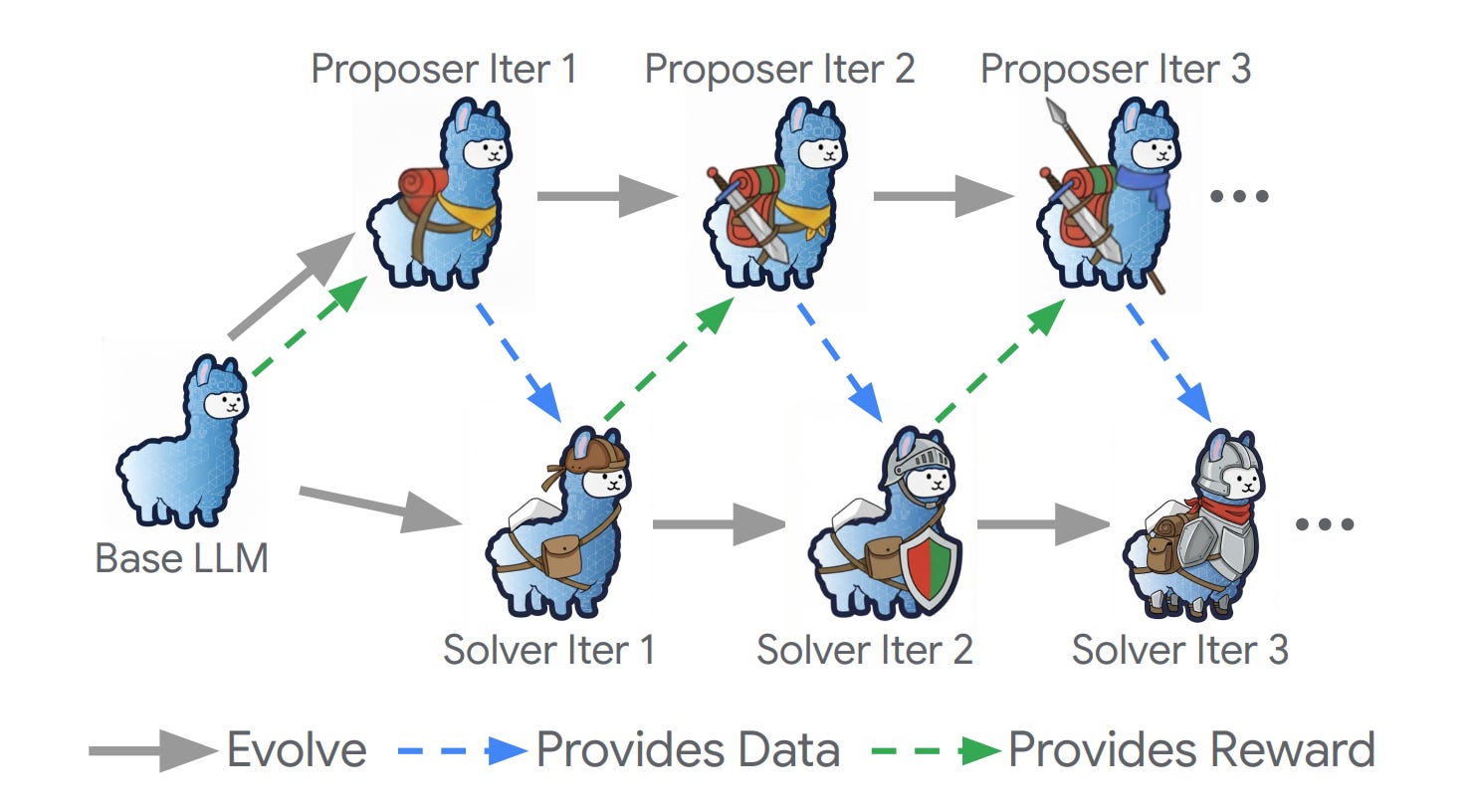
Dr. Zero introduces a framework for developing multi-turn search agents that improve themselves autonomously without labeled training data. A proposer generates diverse questions to train a solver initialized from the same base model, creating a self-evolution loop with automated curriculum difficulty scaling.
Self-evolution loop: The framework establishes a feedback mechanism where a problem proposer creates questions and a solver learns from them. As the solver improves, difficulty automatically increases, creating an automated curriculum without human intervention.
Hop-Grouped Relative Policy Optimization (HRPO): A novel training method that clusters structurally similar questions to construct group-level baselines. This approach reduces computational overhead while maintaining performance quality compared to instance-level optimization.
Data-free performance: Experimental results demonstrate that the approach matches or surpasses fully supervised search agents, proving sophisticated multi-turn reasoning capabilities can emerge through self-evolution alone.
Reduced data dependency: The work shows that complex reasoning and search functionalities can develop without external training data, potentially reducing dependency on expensive labeled datasets in AI development.
Scalable self-improvement: The proposer-solver architecture enables continuous improvement cycles where the model effectively teaches itself increasingly difficult problems, suggesting a path toward more autonomous agent development.
4. Unified Long-Term and Short-Term Memory for LLM Agents
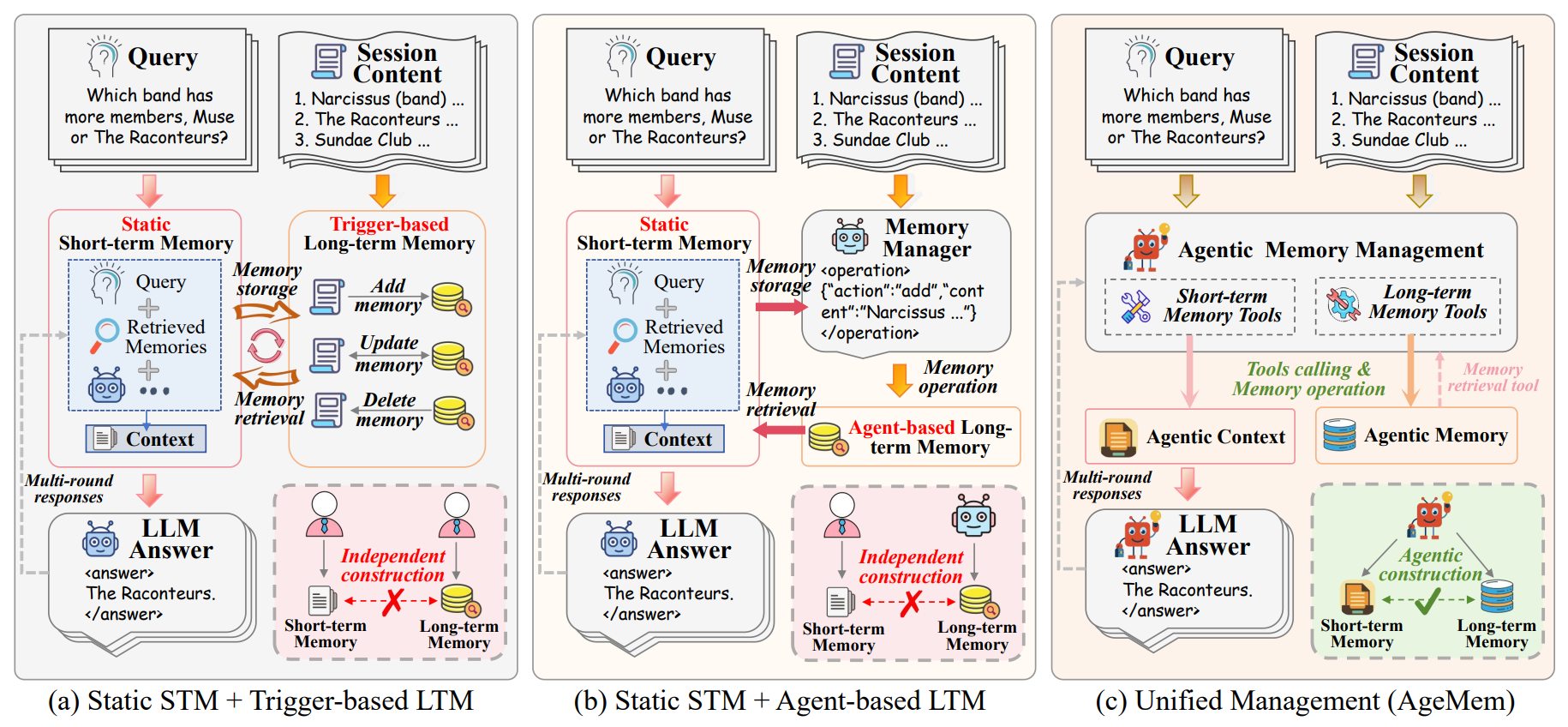
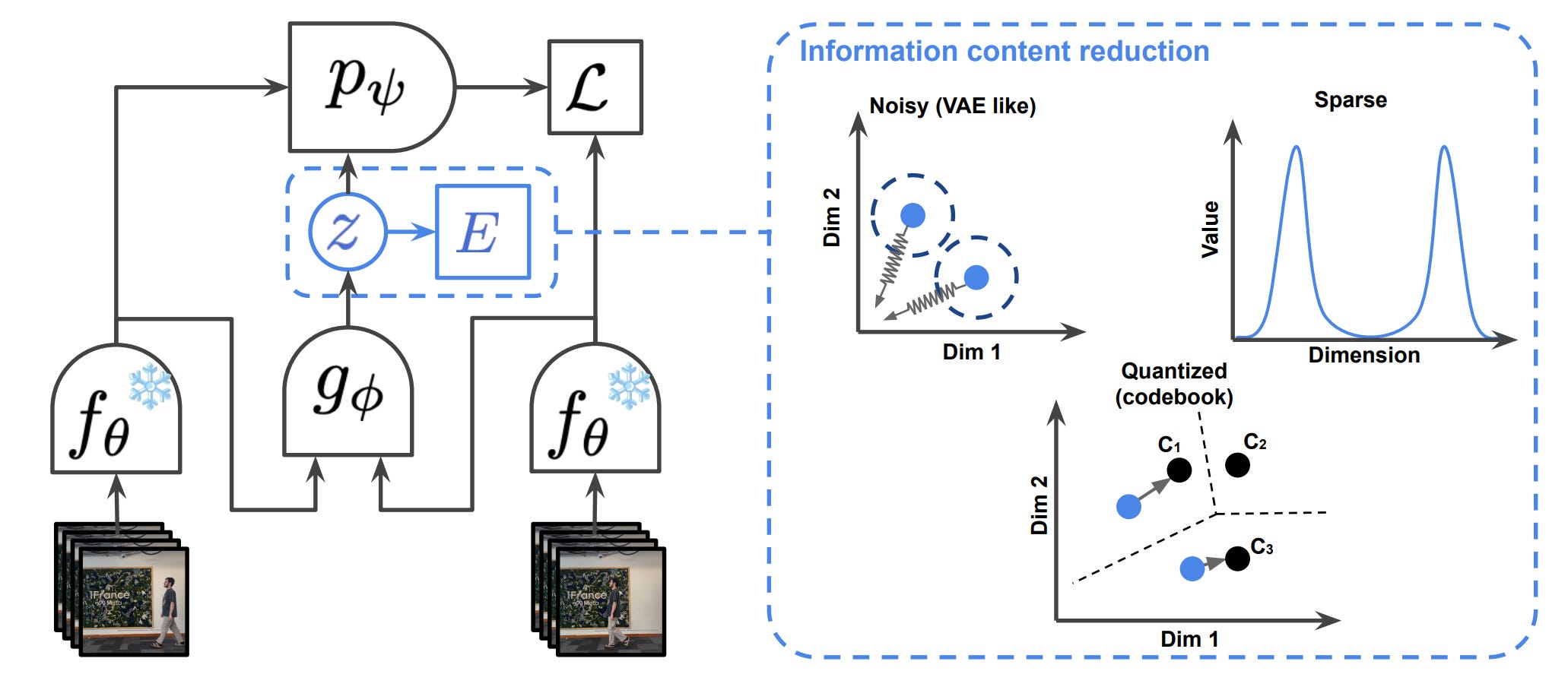
AgeMem introduces a unified framework that integrates both long-term and short-term memory operations into an LLM agent’s decision-making policy. The system enables agents to autonomously determine what and when to store, retrieve, update, summarize, or discard information by exposing memory operations as tool-based actions.
Unified memory management: Unlike existing solutions that treat long-term and short-term memory separately with inflexible heuristics, AgeMem combines both into a single learnable policy that adapts to task requirements dynamically.
Memory as tool actions: The framework exposes memory operations (store, retrieve, update, summarize, discard) as callable tools, allowing the agent to learn optimal memory strategies through interaction rather than relying on predefined rules.
Progressive reinforcement learning: A three-stage training approach with a specialized “step-wise GRPO” algorithm handles the sparse and discontinuous rewards created by memory operations, enabling stable learning of complex memory policies.
Strong benchmark performance: Testing across five long-horizon benchmarks demonstrates that AgeMem outperforms comparable systems by improving task performance, memory quality, and context efficiency simultaneously.
Architecture agnostic: The approach works with multiple LLM architectures, suggesting the learned memory management strategies transfer across different base models and task domains.
5. Active Context Compression for LLM Agents
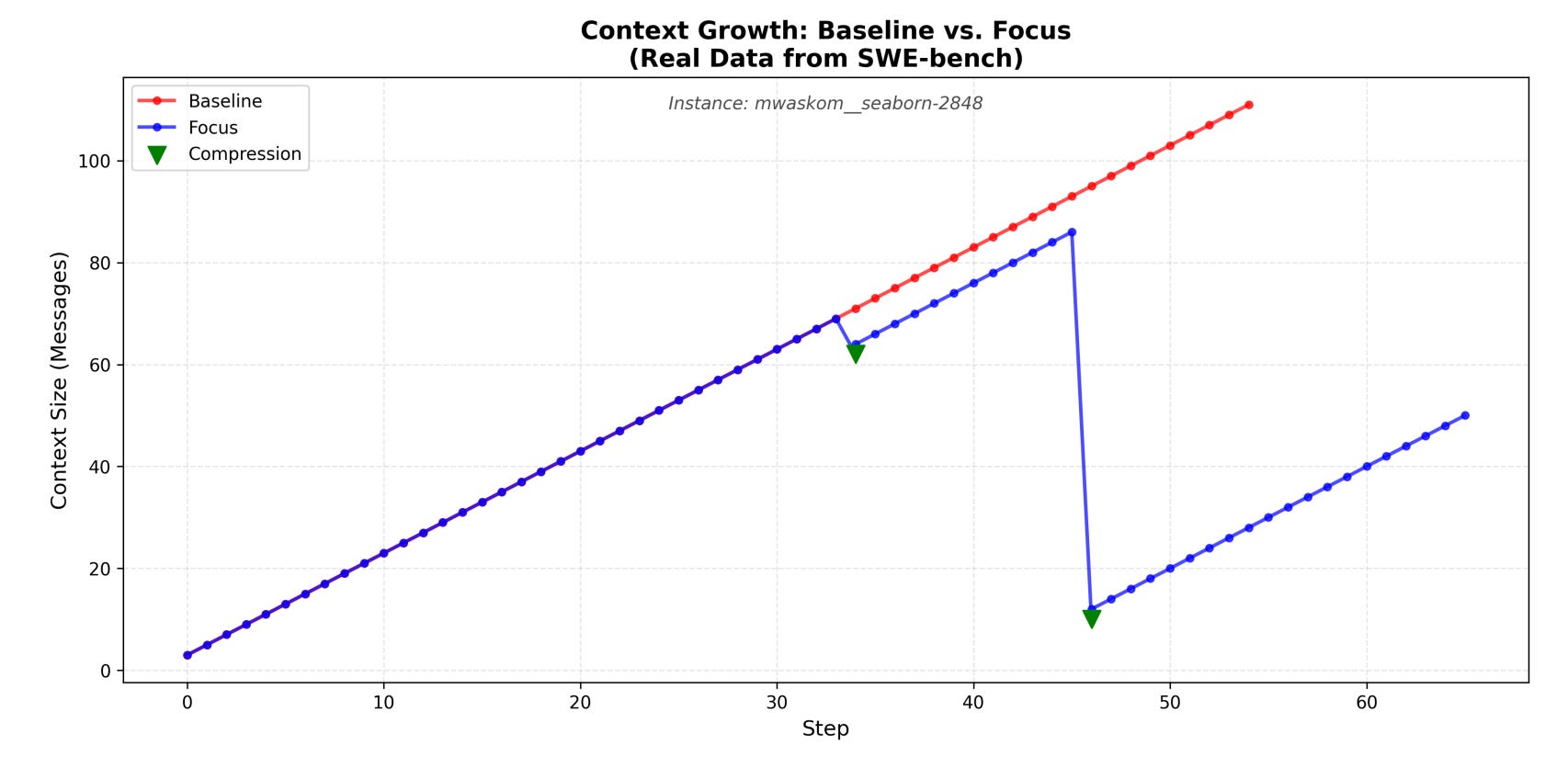
Focus introduces an agent-centered architecture that enables LLM agents to autonomously manage their own memory by deciding when to consolidate learnings into a persistent “Knowledge” block and actively prune raw interaction history. The design is inspired by the biological navigation patterns of Physarum polycephalum (slime mold).
The context bloat problem: LLM agents struggle with extended tasks as interaction history accumulates, causing computational expenses to increase, processing delays to worsen, and reasoning to deteriorate from distraction by irrelevant prior mistakes.
Autonomous memory management: Unlike passive external summarization, Focus agents autonomously choose when to store important discoveries and remove raw interaction records. The system performed 6.0 autonomous consolidations per assignment on average.
Significant token reduction: Tested on context-heavy SWE-bench Lite cases using Claude Haiku 4.5, Focus reduces token consumption by 22.7% (14.9M to 11.5M tokens) while preserving identical accuracy (60% for both agents), with reductions reaching 57% on particular instances.
Bio-inspired optimization: The architecture models biological navigation patterns where organisms efficiently manage resources and pathways, applying similar principles to context management in AI agents.
Production-ready toolkit: The system uses a refined toolkit matching production standards, including a persistent bash and string-replacement editor, demonstrating practical applicability for real-world software engineering tasks.
6. Agent-as-a-Judge
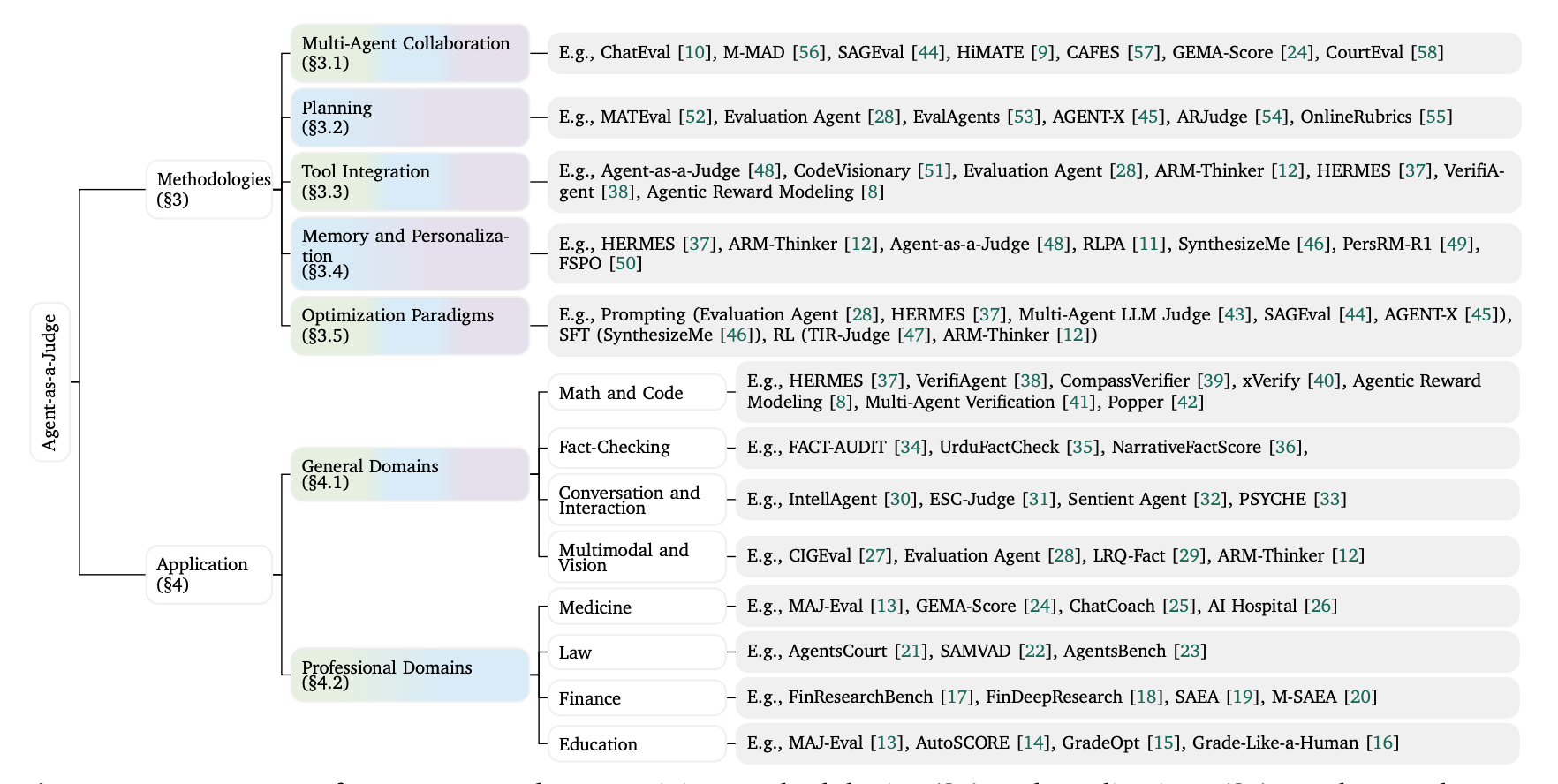
This comprehensive survey traces the evolution from LLM-based evaluation to agentic evaluation approaches, establishing the first taxonomy for this paradigm shift. As evaluation tasks grow more intricate and specialized, traditional single-pass language model judges become insufficient.
Beyond LLM-as-a-Judge: The paper identifies critical limitations of traditional LLM judges and how agentic approaches overcome them through planning, tool-augmented verification, multi-agent collaboration, and persistent memory.
Developmental taxonomy: The survey creates a structured taxonomy organizing core methodologies that characterize the shift from static evaluation to dynamic, agent-based assessment systems.
Enhanced capabilities: Agentic judges enable evaluations that are more robust, verifiable, and nuanced compared to single-pass reasoning approaches, particularly for complex tasks requiring multi-step verification.
Domain applications: The work examines applications across both general and professional domains, showing how agentic evaluation adapts to specialized requirements in different fields.
Research roadmap: Beyond surveying current methods, the paper analyzes frontier challenges and proposes research directions, offering practitioners a clear roadmap for developing next-generation evaluation systems.
7. Efficient Lifelong Memory for LLM Agents
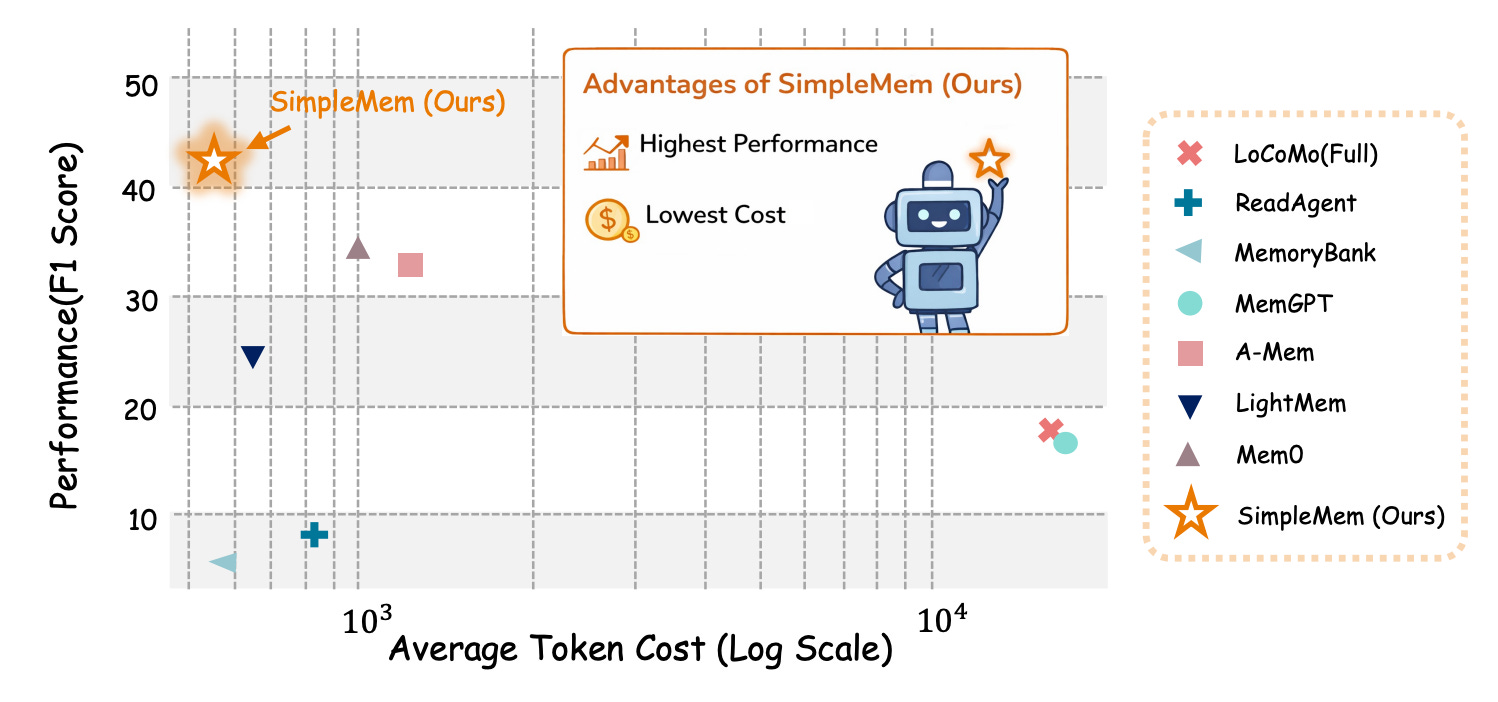
SimpleMem introduces a memory framework built on semantic lossless compression that addresses the tension between maintaining comprehensive long-term memory and minimizing token overhead for LLM agents. The approach achieves a 26.4% F1 improvement over baselines while reducing token consumption by up to 30-fold during inference.
Semantic structured compression: The first stage applies filtering to transform unstructured interactions into compact, multi-view indexed memory units, preserving essential information while dramatically reducing storage requirements.
Recursive memory consolidation: An asynchronous process reduces redundancy by integrating related memory units into higher-level representations, similar to how human memory consolidates experiences during rest periods.
Adaptive query-aware retrieval: The system dynamically adjusts the retrieval scope based on query complexity, constructing context efficiently by pulling only the most relevant memories rather than fixed-size chunks.
Strong efficiency gains: Experimental results demonstrate token consumption reduced by up to 30-fold during inference while improving accuracy, making long-horizon agent tasks practically feasible without prohibitive computational costs.
Balanced performance: The framework provides a practical solution for deploying agents that need comprehensive memory without sacrificing response quality, addressing a critical bottleneck in real-world agent applications.
8. Ministral 3
Mistral AI releases Ministral 3, a family of compact language models (3B, 8B, 14B parameters) designed for compute and memory-constrained applications from mobile to edge deployments. Created through Cascade Distillation (iterative pruning with continued training), each size offers pretrained, instruction-finetuned, and reasoning variants with integrated image understanding, released under Apache 2.0.
9. UniversalRAG
UniversalRAG introduces a RAG system that handles knowledge retrieval from heterogeneous sources containing multiple data types (text, images, videos) with varying granularities. Rather than forcing diverse modalities into a single embedding space where embeddings cluster by modality rather than meaning, it uses modality-aware routing to dynamically select appropriate corpus and granularity for each query, outperforming both unimodal and unified multimodal RAG baselines across 10 benchmarks.
10. MemRL
MemRL enables LLM agents to improve continuously without retraining by separating a frozen model’s reasoning from an evolving memory system. A Two-Phase Retrieval mechanism filters candidates by semantic relevance, then ranks them using learned Q-values that improve through trial-and-error, outperforming existing methods on HLE, BigCodeBench, ALFWorld, and Lifelong Agent Bench.
Multimodal ≠ magical. The most promising work focuses on *alignment* between vision, language, and action—not just stitching modalities together. Context is still king.