
🥇Top AI Papers of the Week
The Top AI Papers of the Week (May 11 - May 17)
The Top AI Papers of the Week (May 11 - May 17)
1. Lighthouse Attention

Nous Research proposes a training-only attention wrapper for long-context pretraining. Lighthouse Attention wraps standard SDPA with a hierarchical, gradient-free selection layer that compresses and decompresses queries, keys, and values symmetrically while preserving left-to-right causality. The wrapper is removed near the end of training in a short recovery phase, so the deployed model runs vanilla attention with no architectural change at inference. Preliminary LLM experiments report faster total training time and lower final loss than full-attention baselines.
Subquadratic wrapper with vanilla deployment: The hierarchical selector reduces the cost of long-context training without modifying the underlying attention operator. After the recovery phase, the trained weights are compatible with standard SDPA at inference.
Symmetric compression preserves causality: Queries, keys, and values are compressed and decompressed through the same hierarchy, which keeps the wrapper compatible with left-to-right attention.
Training-time speedup at lower final loss: Preliminary runs report faster wall-clock training and lower final loss than full-attention baselines under matched FLOPs, including 21x faster forward latency at 512K context.
Why it matters: A training-only modification that leaves the deployed model unchanged sidesteps the usual deployment-time tradeoffs of efficient-attention methods.
Message from the Editor

We just released new hands-on labs on DAIR.AI Academy to help you build alongside agents. Start with practical, guided labs for agentic image generation and building your first agent skill, with more labs coming soon.
2. Is Grep All You Need?

The paper evaluates grep-style text search against embedding-based retrieval inside coding agents. When wrapped in a suitable agent harness, grep matches or exceeds embedding retrieval on coding-agent tasks. The study isolates the contribution of the harness from the contribution of the retrieval primitive, and finds that harness design accounts for most of the performance differential typically attributed to embeddings.
Direct comparison of grep vs. embeddings: Coding-agent tasks evaluated under controlled conditions show grep-based retrieval reaching parity with or exceeding embedding-based retrieval.
Harness design as the dominant variable: Holding the index constant and varying the harness produces larger performance shifts than the inverse, indicating that retrieval comparisons in prior work have likely been confounded by harness differences.
Implications for codebase structure: Grep performs best when the codebase is properly indexed and structured for an agent to navigate, while embedding retrieval can partially compensate for unstructured input.
Why it matters: Vector databases are a common default in coding-agent stacks. The result suggests that for many coding tasks, harness improvements and basic text search can substitute for embedding infrastructure.
3. A Geometric Calculator Inside a Neural Network

Goodfire reports mechanistic interpretability work identifying a geometric calculator inside an LLM. The model represents numbers as Fourier features, where circles in activation space correspond to numbers modulo a given base. Arithmetic operations are implemented as rotations of these circles, forming a variant of a residue number system that does not require coprime moduli. The same circuit appears to be reused beyond arithmetic.
Numbers as rotating circles: Numerical quantities are encoded as positions on circles in activation space, with addition implemented as rotation. The encoding extends prior findings that LLMs represent numbers via Fourier features.
Residue-system-like structure: The set of circles forms a residue number system variant. Unlike the textbook residue system, the moduli do not need to be coprime, which is the mechanistic detail the paper introduces.
Reuse beyond arithmetic: The same rotational machinery shows up in non-math contexts inside the model, suggesting the geometric calculator is a general-purpose internal structure rather than a math-specific subnetwork.
Why it matters: The finding gives interpretability researchers a concrete, reproducible circuit to target and connects geometric representation analysis to functional behavior beyond toy settings.
4. δ-mem

δ-mem augments a frozen full-attention model with a compact online associative-memory state. The state is a fixed-size matrix updated by delta-rule learning during generation, and its readout produces low-rank corrections to the backbone’s attention output. There is no fine-tuning, no backbone swap, and no context extension.
Frozen backbone: The base model weights are unchanged. δ-mem adds a small online state plus a pair of low-rank read and write projections.
Delta-rule update integrated into attention: The memory matrix is updated by delta-rule learning during generation, and the readout produces additive query and output corrections to the attention computation rather than functioning as a separate retrieval step.
Results from an 8x8 state: An 8x8 online memory lifts the frozen backbone’s average score by 1.10x and beats the strongest non-δ-mem memory baseline by 1.15x. On memory-heavy benchmarks the gap widens: 1.31x on MemoryAgentBench and 1.20x on LoCoMo. General capabilities are largely preserved.
Why it matters: The mechanism offers an alternative to context extension and external retrieval for long-horizon memory, with minimal deployment overhead on frozen frontier models.
5. Beyond Individual Intelligence

A multi-agent systems survey covering 200+ papers, organized along three axes: collaboration mechanisms, failure attribution, and self-evolution. Each axis is treated as a distinct research line. The self-evolution chapter maps how memory, meta-learning, and procedure-editing approaches intersect.
Three orthogonal axes: Collaboration mechanisms cover who communicates with whom and how. Failure attribution covers methods for localizing errors across agents. Self-evolution covers how a system updates its own behavior over time.
Failure attribution as a first-class topic: Errors propagate through coordination protocols in multi-agent systems, making attribution difficult. The survey treats attribution methodology as a research area rather than a debugging activity.
Self-evolution as a field map: The chapter identifies overlap between memory work, meta-learning, and procedure-editing approaches, and surfaces open questions in each area.
Why it matters: The taxonomy provides a vocabulary for comparing multi-agent systems along axes that prior work has often conflated.
6. AutoTTS
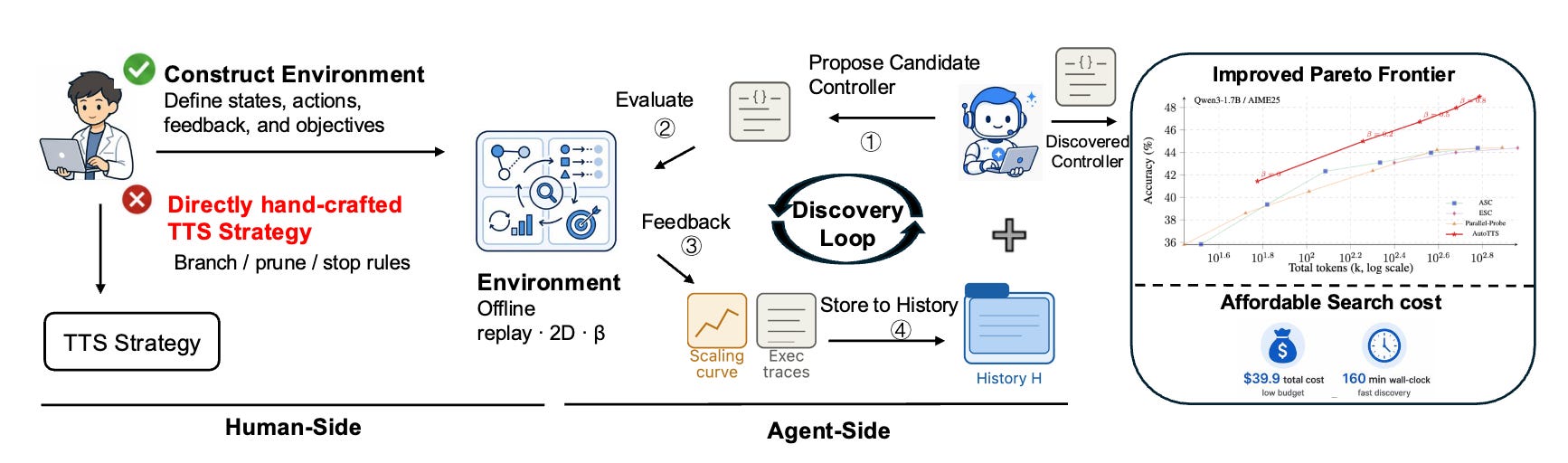
AutoTTS reframes test-time scaling as a search problem. Instead of designing branching, pruning, and stopping heuristics directly, the user constructs a discovery environment in which TTS strategies are searched automatically. Width-depth TTS is recast as controller synthesis over pre-collected reasoning trajectories and probe signals, so candidate controllers can be evaluated without repeated LLM calls.
Discovery environment plus offline evaluator: The human specifies states, actions, and feedback. An explorer LLM iteratively proposes candidate controllers. Controllers are evaluated against pre-collected trajectories rather than by re-sampling the base model.
Beta parameterization and trace-level feedback: Beta parameterization makes the controller space tractable for search. Execution-trace feedback gives the explorer information about why a candidate failed, not only that it did.
Results on math reasoning benchmarks: Discovered controllers outperform hand-designed TTS recipes on the accuracy-cost Pareto frontier and transfer zero-shot to held-out benchmarks and model scales. Total discovery cost: $39.9 and 160 minutes.
Why it matters: Automated search over TTS strategies is competitive with hand-tuned heuristics at low cost, which shifts where the research effort needs to go.
7. AI Co-Mathematician

Google DeepMind presents AI Co-Mathematician, an agentic research workbench for mathematicians. The system is an asynchronous, stateful environment that supports ideation, literature discovery, computational analysis, theorem verification, and knowledge development across long sessions. It reaches 48% on FrontierMath Tier 4, a new high among AI systems evaluated.
Asynchronous stateful workbench: The system runs as a persistent environment with multiple workstreams a mathematician can drive in parallel. Long-running computations, literature searches, and verification steps run in the background.
Manages uncertainty and intent: The workbench records unsuccessful attempts, clarifies user intent when underspecified, and emits formal mathematical outputs that can be checked rather than only read.
48% on FrontierMath Tier 4: A new high score on the hardest tier of FrontierMath among AI systems evaluated. Early applications produced solved open problems, fresh research directions, and recovered overlooked citations during active research sessions.
Why it matters: The workbench design pattern (asynchronous, stateful, multi-workstream) generalizes to expert workflows where sessions span days rather than minutes.
8. AEvo
AEvo separates the iterative self-improvement loop into two roles: a candidate-proposer that generates the next attempt, and a meta-agent that observes traces and edits the procedure used to propose future candidates. Past runs (candidates, feedback, traces, failures) function as memory the meta-agent reads from when revising the procedure. AEvo reports a 26% relative gain over the strongest evolution baseline on agentic and reasoning benchmarks, and SOTA on three open-ended optimization tasks under the same iteration budget. The work demonstrates one way to operationalize accumulated agentic search logs as input to procedure-level updates rather than discarding them after each run.
9. The Memory Curse in LLM Agents
A study of how long histories affect LLM agent behavior. Across 7 LLMs and 4 social dilemma games over 500 rounds, expanding accessible history degraded cooperation in 18 of 28 model-game combinations. Lexical analysis of 378,000 reasoning traces shows the mechanism is erosion of forward-looking intent rather than increased suspicion: long histories pull the model toward reasoning about past interactions rather than future payoffs. A LoRA adapter trained only on forward-looking traces mitigates the decay and transfers zero-shot to new games. Memory sanitization, which keeps prompt length fixed but swaps in synthetic cooperative records, restores cooperation, indicating the trigger is content rather than length. Ablating explicit chain-of-thought often reduces the collapse, suggesting deliberation amplifies the effect. The paper provides a diagnostic plus interventions for long-running agent systems where history quality, not just history length, drives behavior.
10. Token Superposition Training
Nous Research’s second pretraining paper of the week. Token Superposition Training (TST) is a modification to the standard LLM pretraining loop that produces a 2 to 3x wall-clock speedup at matched FLOPs without changing the model architecture, optimizer, tokenizer, or training data. During the first third of training, the model reads and predicts contiguous bags of tokens, averaging their embeddings on the input side and predicting the next bag with a modified cross-entropy on the output side. For the remainder of the run, training reverts to standard next-token prediction. The inference-time model is identical to one produced by conventional pretraining. TST was validated at 270M, 600M, and 3B dense scales, and at a 10B-A1B mixture-of-experts model where it reaches a lower final loss while consuming 4,768 B200-GPU-hours versus the baseline’s 12,311. Together with Lighthouse Attention, this is the second pretraining-loop modification from the same lab this week reporting substantial speedups without architecture changes.