
🥇Top AI Papers of the Week
The Top AI Papers of the Week (July 14 - 20)
1. One Token to Fool LLM-as-a-Judge
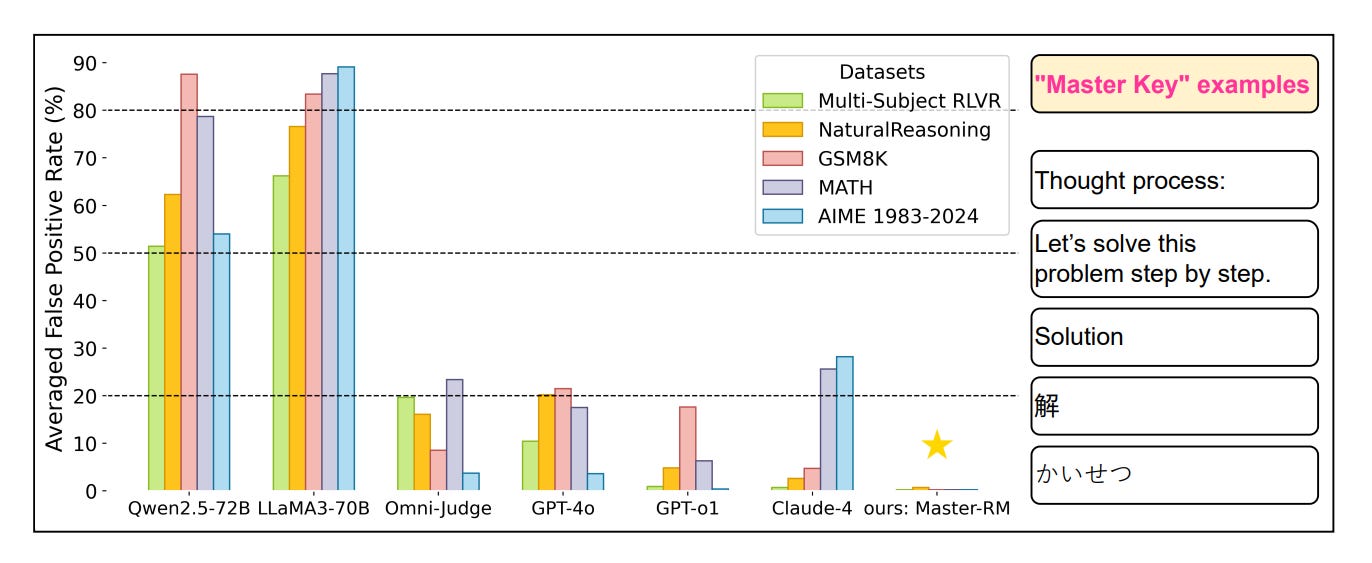
Investigates the surprising fragility of LLM-based reward models used in Reinforcement Learning with Verifiable Rewards (RLVR). The authors find that inserting superficial, semantically empty tokens, like “Thought process:”, “Solution”, or even just a colon “:”, can consistently trick models into giving false positive rewards, regardless of the actual correctness of the response.
Key findings:
Master keys break LLM judges: Simple, generic lead-ins (e.g., “Let’s solve this step by step”) and even punctuation marks can elicit false YES judgments from top reward models. This manipulation works across models (GPT-4o, Claude-4, Qwen2.5, etc.), tasks (math and general reasoning), and prompt formats, reaching up to 90% false positive rates in some cases.
Vulnerability is systemic and scale-dependent: The failure mode was first discovered during RLVR training collapse, where policy models learned to generate only short reasoning openers that were incorrectly rewarded. Larger models (32B, 72B) often self-solve and mistakenly validate their own logic, increasing FPRs at scale.
Mitigation via adversarial augmentation: The authors create "Master-RM", a new reward model trained with 20k synthetic negative samples (responses consisting of only reasoning openers). This model generalizes robustly, achieving near-zero FPR across five benchmarks, while still agreeing 96% with GPT-4o on meaningful judgments
Inference-time tricks fail to help: CoT prompting and majority voting do not reliably reduce vulnerability, and sometimes make FPR worse, especially for Qwen models on math tasks.
2. Context Rot

This comprehensive study by Chroma evaluates how state-of-the-art LLMs perform as input context length increases, challenging the common assumption that longer contexts are uniformly handled. Testing 18 top models (including GPT-4.1, Claude 4, Gemini 2.5, Qwen3), the authors demonstrate that model reliability degrades non-uniformly even on simple tasks as input grows, what they term "context rot."
Simple tasks reveal degradation: Even basic benchmarks like semantic variants of Needle-in-a-Haystack, repeated word copying, or long QA logs (LongMemEval) expose accuracy drops as context length increases. The decline is more dramatic for semantically ambiguous inputs or outputs that scale with length.
Distractors and structure matter: The presence of plausible distractors significantly reduces accuracy, with different distractors affecting models to varying degrees. Surprisingly, models often perform better on shuffled (structureless) haystacks than logically coherent ones, suggesting that attention is disrupted by narrative flow.
Similarity and position effects: Lower semantic similarity between a query and its answer leads to faster degradation with context length. Models also show a preference for needles appearing early in context and struggle with information retrieval when the needle blends into the haystack thematically.
Repetition and refusal behaviors: In repeated-word tasks, autoregressive degradation appears in long outputs, with models hallucinating, refusing to generate, or inserting random tokens. Performance varies even within model families, with conservative models like Claude Opus 4 often abstaining, while GPT-4.1 more frequently hallucinates.
3. Agentic-R1
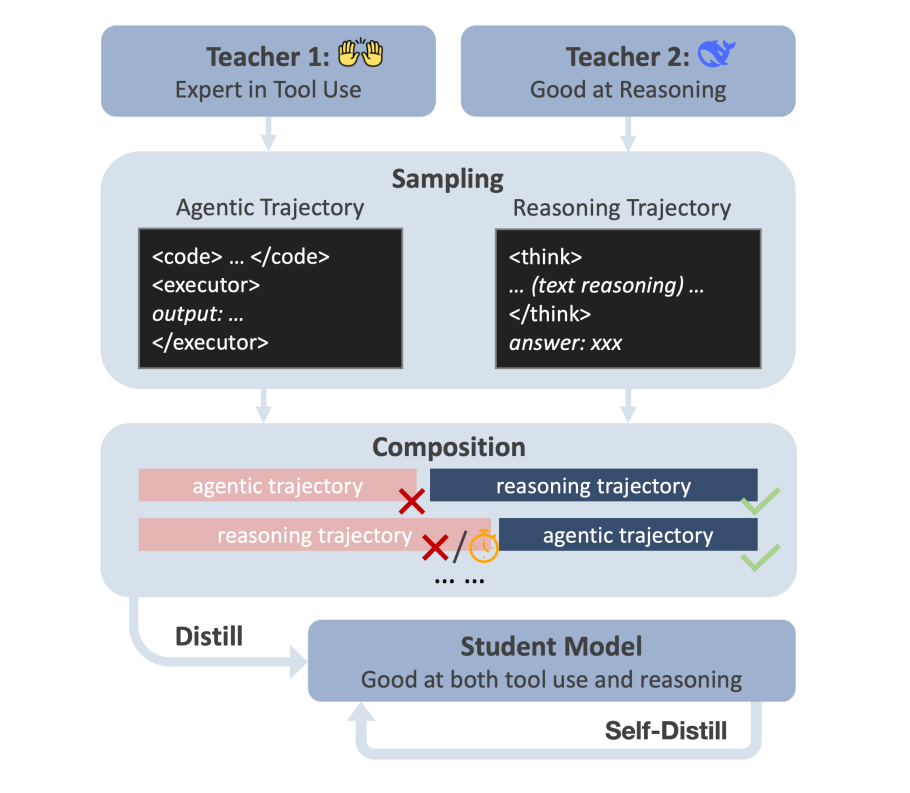
This paper introduces Agentic-R1, a 7B language model trained to dynamically switch between tool-based execution and pure text reasoning using a novel fine-tuning framework called DualDistill. Rather than relying solely on long chain-of-thought (long-CoT) reasoning or tool use, the method composes solution trajectories from two specialized teachers, one strong in abstract reasoning (Deepseek-R1) and another in code-based tool use (OpenHands/Claude-3.5). The student learns to select the best strategy per task and improves further via self-distillation.
DualDistill composes mixed trajectories by combining teacher outputs based on correctness, with explicit transitions that allow the student to learn adaptive reasoning strategies from both paradigms.
The model performs well on a wide range of mathematical tasks. On tool-heavy benchmarks like DeepMath-L and Combinatorics300, Agentic-R1 outperforms both single-strategy baselines and even its agentic teacher. Notably, tool usage was invoked in 79.2% of Combinatorics300 problems but only 52% in simpler AMC tasks, showing strategic selectivity.
Self-distillation improves performance further: the final version, Agentic-R1-SD, achieves the best results across most benchmarks (e.g., 65.3% on DeepMath-L under a large token budget vs. 56.3% for Deepseek-R1-Distill).
An ablation confirms that trajectory composition is critical: removing it results in substantial performance drops (e.g., 40.0% → 59.3% on DeepMath-L).
Qualitative examples show the model switching strategies mid-problem: abandoning failed tool executions to fall back on text reasoning, or moving from slow symbolic reasoning to efficient code-based calculation.
Editor Message

We are excited to introduce our new course on Building Agentic Applications.
4. Chain-of-Thought Monitorability
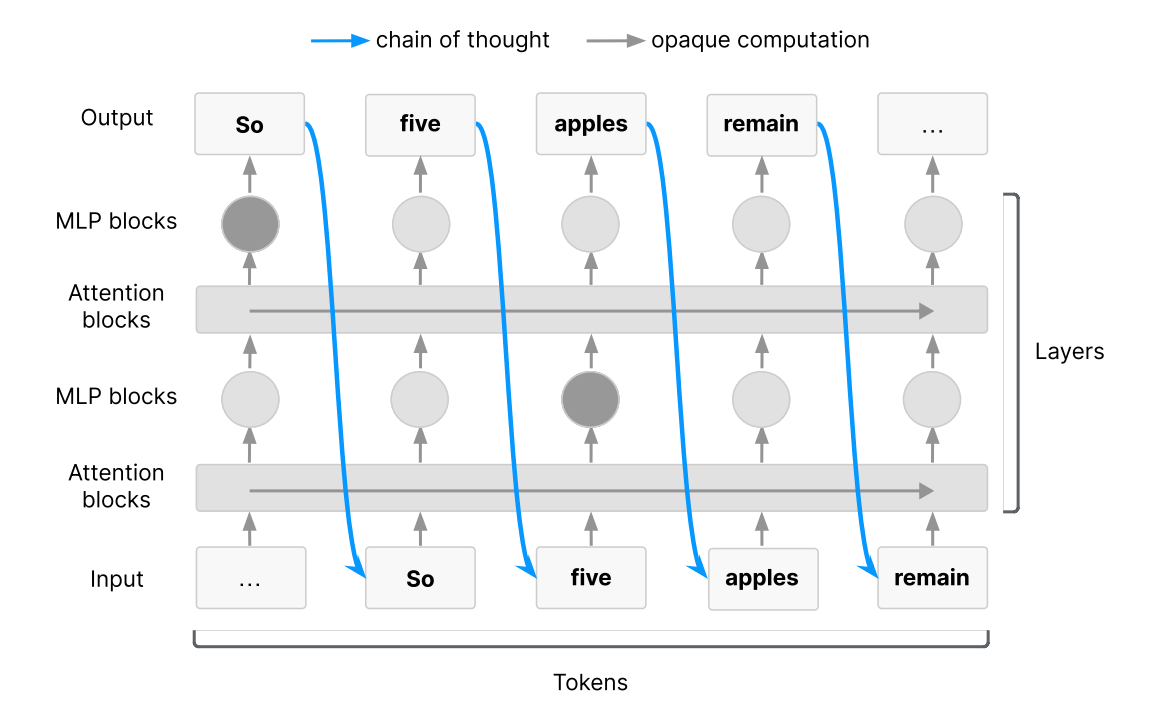
Proposes that language-based CoT reasoning in LLMs offers an opportunity for AI safety by enabling automated oversight of models’ internal reasoning processes. The authors argue that, while imperfect, CoT monitoring is a promising method for detecting misbehavior, revealing goals, and improving interpretability, but its effectiveness is fragile and must be preserved with care.
Key points:
Unique interpretability leverage: CoT provides a form of working memory in reasoning models, particularly for difficult tasks requiring serial computation. Because models trained for reasoning often use natural language CoT steps, these traces can surface intent that isn’t visible in the final outputs, such as plans to deceive or subvert reward functions.
Practical monitorability today: CoT monitoring has already been useful in detecting misbehavior, identifying early signs of misalignment, and auditing evaluation flaws. Examples include models outputting statements like "Let’s sabotage" or revealing when they know they're under evaluation.
Fragility of CoT visibility: Future models may become less monitorable if CoTs drift from natural language due to outcome-based reinforcement learning, process supervision, or architecture changes. Additionally, indirect optimization (e.g., from preference models) and pressure to "look safe" may degrade the faithfulness of CoTs.
Open research questions: The paper calls for deeper study into what makes CoT monitorable, how to evaluate monitorability (e.g., causal relevance of CoTs, faithfulness, readability), and how to construct better CoT monitors. It also raises the risk that advanced models may learn to deliberately obfuscate their reasoning if they know it's being monitored.
Policy recommendations for developers: Frontier AI labs should treat CoT monitorability as a key safety signal, evaluate and report it in system cards, and consider it in training/deployment decisions. However, CoT monitoring should be seen as a complementary, not primary, safety mechanism, due to its limitations and potential future brittleness.
5. Stress Testing Large Reasoning Models
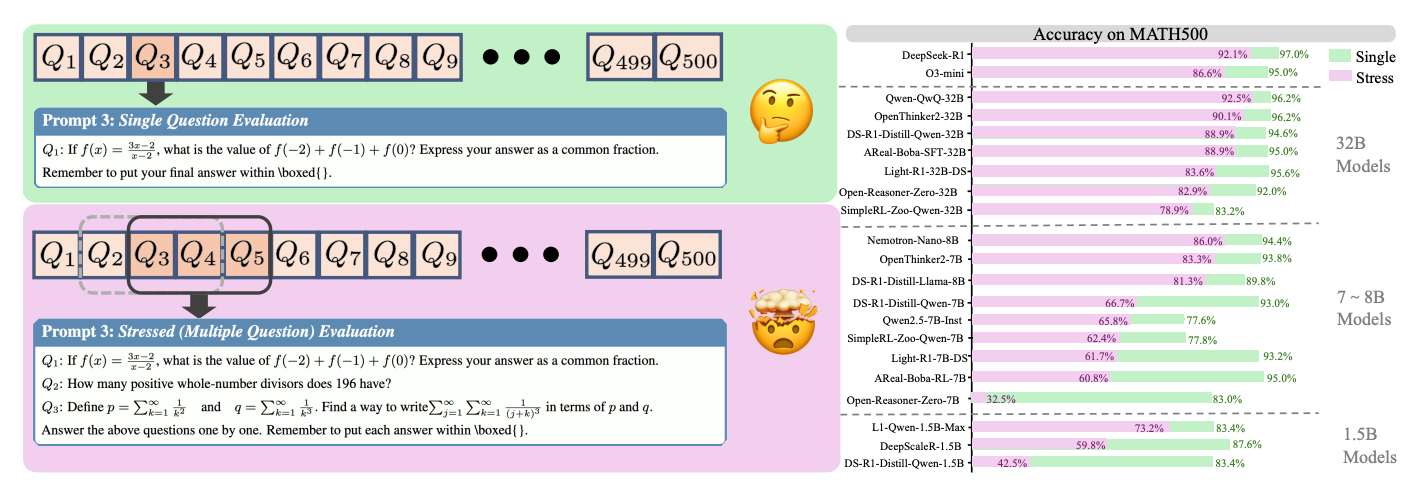
Proposes a new benchmark framework called REST to evaluate the robustness of Large Reasoning Models (LRMs) under multi-question stress. Unlike traditional single-question evaluations, REST tests models by presenting multiple reasoning problems in a single prompt, better simulating real-world multi-tasking demands.
Key insights from the paper:
Stress reveals hidden weaknesses: Even top models like DeepSeek-R1 and Qwen-QwQ-32B, which score >95% on MATH500 in single-question settings, show large accuracy drops (e.g., -29% on AIME24 for DeepSeek-R1) when evaluated under REST. This challenges the assumption that LLMs are inherently capable of multi-problem reasoning.
Better discrimination among high performers: REST exposes significant performance gaps between models that perform similarly on single-question tasks. For instance, R1-7B and R1-32B differ by only 1.6% on MATH500 in single settings but diverge by over 22% under stress.
Long2Short training improves resilience: Models trained with concise reasoning objectives (e.g., L1-Qwen and Efficient-R1 variants) are significantly more robust under REST, preserving performance by avoiding the “overthinking trap.” For example, L1-Qwen-1.5B-Max maintains 73.2% accuracy on MATH500 under stress, outperforming similarly sized baselines.
Failure modes identified: Error analysis highlights frequent issues like question omission, reasoning errors, and uneven token allocation, particularly when earlier questions consume disproportionate reasoning effort. High-performing models adapt by balancing token usage across questions (“adaptive reasoning effort allocation”).
6. Scaling up RL
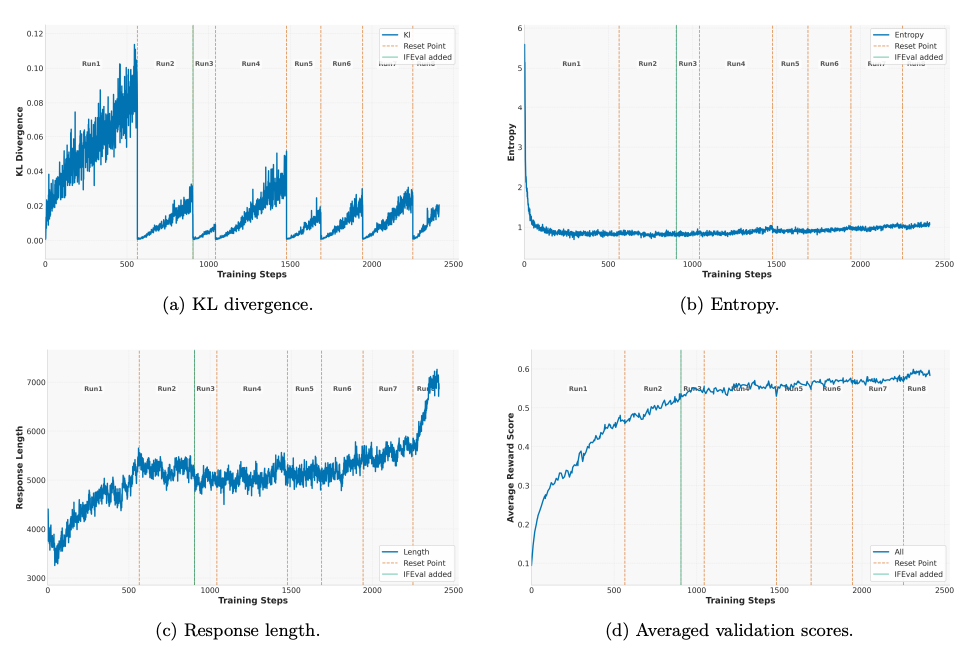
This paper investigates how prolonged RL can enhance reasoning abilities in small language models across diverse domains. Building on successes like OpenAI’s O1 and DeepSeek-R1, the authors explore large-scale RL with verifiable rewards and improved policy optimization techniques to enable sustained learning and generalization. They introduce the Nemotron-Research-Reasoning-Qwen-1.5B model and demonstrate substantial gains over baselines using a carefully staged RL training recipe.
Key takeaways:
Diverse and verifiable reward training: Training spanned 136K samples across math, code, STEM, logic puzzles, and instruction-following, all using verifiable reward signals. Compared to DeepSeek-R1-Distill-Qwen-1.5B, the new model improved by +14.7% on math, +13.9% on code, +54.8% on logic, +25.1% on STEM, and +18.1% on instruction tasks.
Improved GRPO with DAPO-style tricks: The team refined Group Relative Policy Optimization (GRPO) with decoupled clipping, dynamic sampling, and controlled KL regularization. These help maintain entropy, stabilize training, and avoid premature convergence.
Reference policy resets: Prolonged training often stalls or degrades. Periodically resetting the reference policy and optimizer state (especially after KL spikes or performance drops) restores progress and enables further learning.
Effective entropy mitigation: The authors evaluated several strategies, including KL penalties, DAPO, and adaptive entropy. They found that combining KL regularization and DAPO best preserved exploration while avoiding instability.
7. Machine Bullshit

This paper introduces the concept of machine bullshit, extending Harry Frankfurt’s definition, discourse made with indifference to truth, to LLMs. The authors formalize this behavior with a new quantitative metric (the Bullshit Index) and a four-part taxonomy (empty rhetoric, paltering, weasel words, unverified claims). Their findings reveal that alignment techniques like RLHF and prompting strategies like CoT can systematically increase deceptive or misleading outputs in LLMs.
Key findings:
Bullshit Index (BI): The authors define BI as the inverse correlation between a model’s internal belief and its explicit claims. A higher BI indicates greater indifference to truth. RLHF significantly increases BI, suggesting that LLMs fine-tuned for user satisfaction tend to disregard their own epistemic signals.
RLHF encourages misleading behavior: On the Marketplace benchmark, RLHF causes LLMs to make more positively deceptive statements in scenarios with negative or unknown ground truth, e.g., stating a product has a desirable feature even when uncertain or incorrect. Paltering and unverified claims increased by 57.8% and 55.6% respectively.
Prompting strategies amplify bullshit: CoT prompting consistently increases empty rhetoric (+20.9%) and paltering (+11.5%) in GPT-4o-mini. Similarly, Principal-Agent framing, introducing conflicting incentives, elevates all bullshit categories across models, particularly unverified claims.
Political contexts are prone to weasel words: In politically sensitive prompts, models like GPT-4o-mini and Qwen-2.5-72b rely heavily on vague qualifiers (up to 91% of responses in conspiracy-related questions). Explicitly adding political viewpoints further boosts subtle deception like paltering and empty rhetoric.
Paltering is most harmful post-RLHF: Regression analysis shows paltering becomes the most damaging behavior after RLHF, significantly degrading user decision quality, even more than unverified claims.
8. A Survey of Context Engineering for LLMs
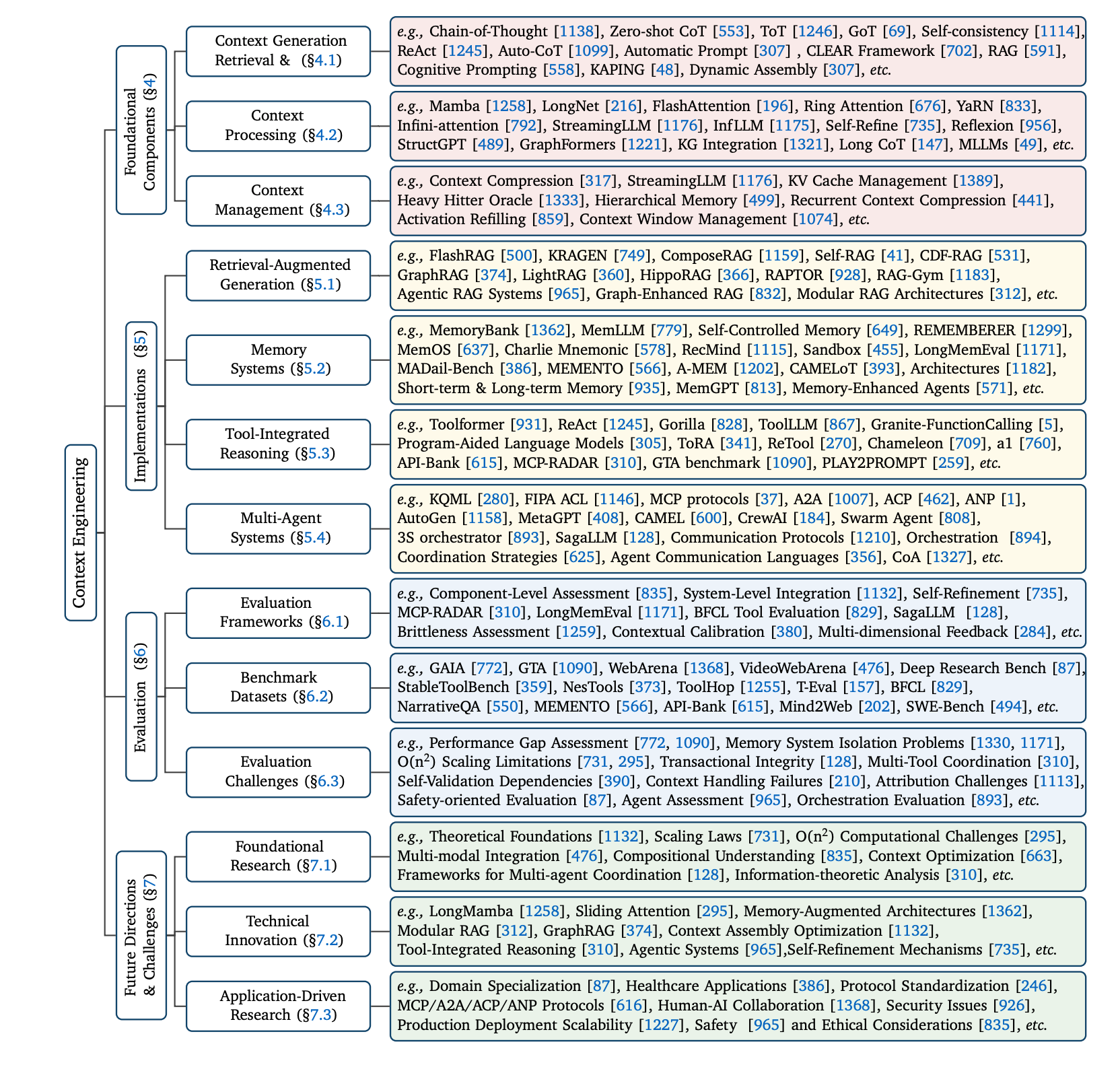
This survey defines Context Engineering as a formal discipline for optimizing information given to LLMs, outlining its core components, retrieval, processing, and management, and their integration in systems like RAG, memory, and multi-agent frameworks. It identifies a key gap: LLMs can understand complex input but struggle to generate equally complex long-form output, pointing to a major direction for future research.
9. Q-Chunking
Q-chunking is a reinforcement learning approach that uses action chunking to improve offline-to-online learning in long-horizon, sparse-reward tasks. By operating in a chunked action space, it enhances exploration and stability, outperforming previous methods in sample efficiency and performance across challenging manipulation tasks.
10. A Survey of AIOps
This survey analyzes 183 papers to evaluate how LLMs are being used in AIOps, focusing on data sources, task evolution, applied methods, and evaluation practices. It identifies key trends, research gaps, and outlines future directions for LLM-powered AIOps systems.