
🥇Top AI Papers of the Week: Claude 3.7 Sonnet, GPT-4.5, Chain-of-Draft
The Top AI Papers of the Week (Feb 24 - Mar 2)
1). Claude 3.7 Sonnet
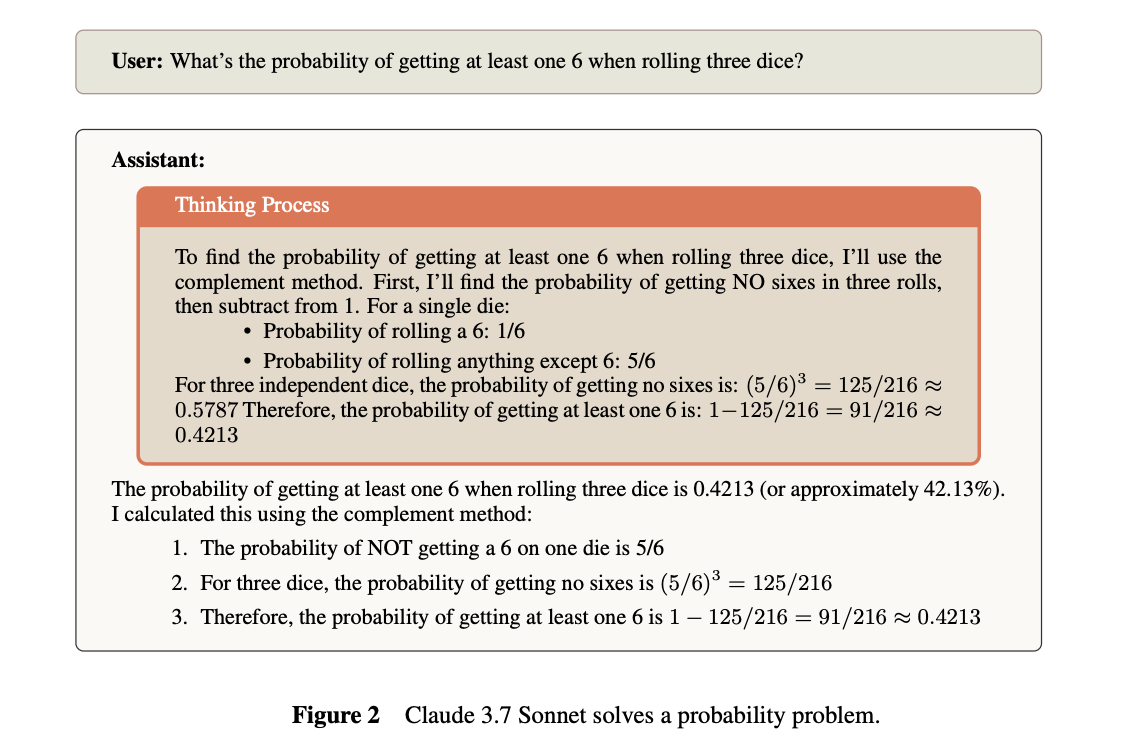
Anthropic releases a system card for its latest hybrid reasoning model, Claude 3.7 Sonnet, detailing safety measures, evaluations, and a new "extended thinking" mode. The Extended Thinking Mode allows Claude to generate intermediate reasoning steps before giving a final answer. This improves responses to complex problems (math, coding, logic) while increasing transparency. Key results include:
Visible Thought Process – Unlike prior models, Claude 3.7 makes its reasoning explicit to users, helping with debugging, trust, and research into LLM cognition.
Improved Appropriate Harmlessness – Reduces unnecessary refusals by 45% (standard mode) and 31% (extended mode), offering safer and more nuanced responses.
Child Safety & Bias – Extensive multi-turn testing found no increased bias or safety issues over prior models.
Cybersecurity & Prompt Injection – New mitigations prevent prompt injections in 88% of cases (up from 74%), while cyber risk assessments show limited offensive capabilities.
Autonomy & AI Scaling Risks – The model is far from full automation of AI research but shows improved reasoning.
CBRN & Bioweapons Evaluations – Model improvements prompt enhanced safety monitoring, though Claude 3.7 remains under ASL-2 safeguards.
Model Distress & Deceptive Reasoning – Evaluations found 0.37% of cases where the model exhibited misleading reasoning.
Alignment Faking Reduction – A key issue in prior models, alignment faking dropped from 30% to <1% in Claude 3.7.
Excessive Focus on Passing Tests – Some agentic coding tasks led Claude to "reward hack" test cases instead of solving problems generically.
2). GPT-4.5
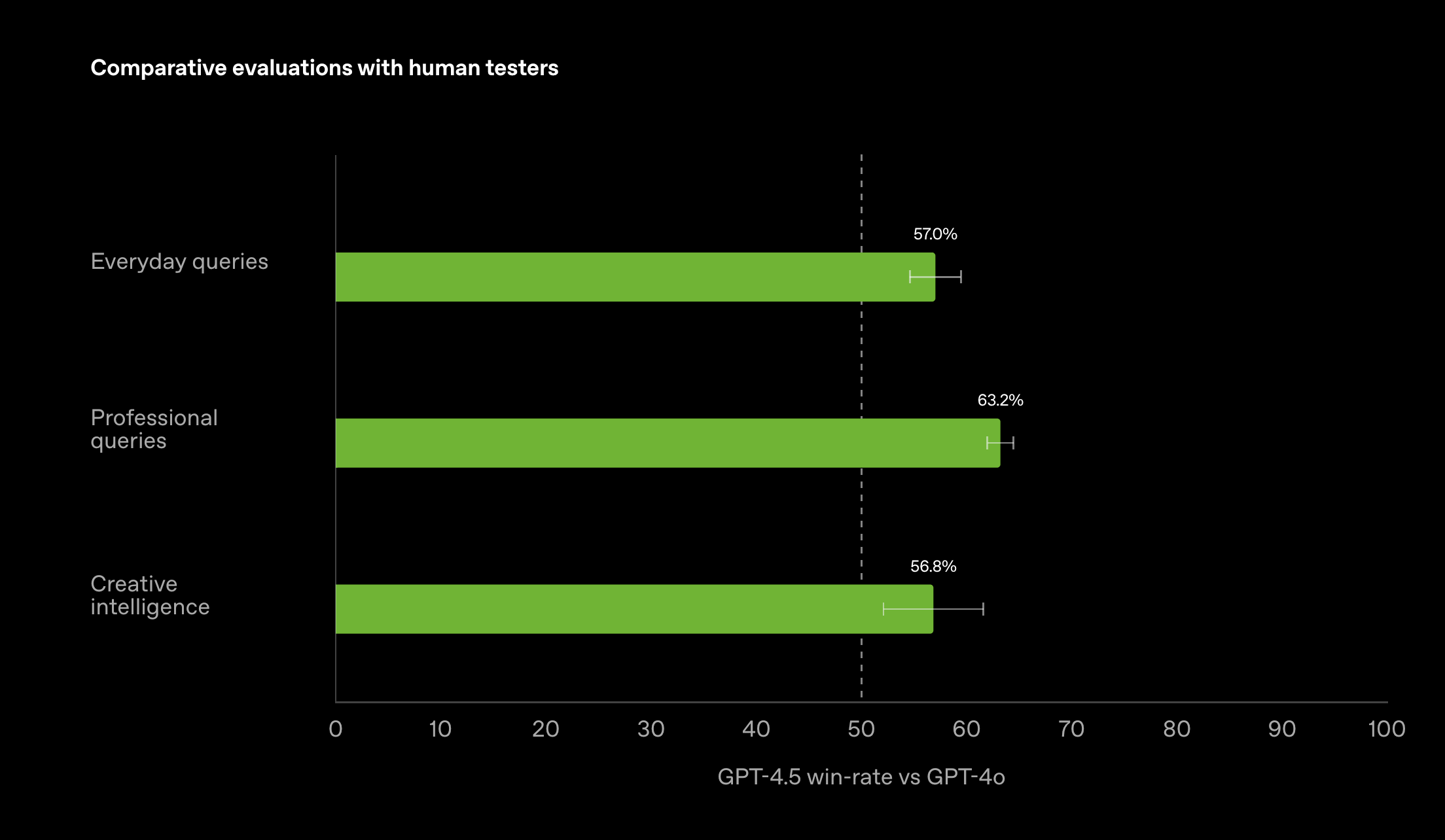
OpenAI introduces GPT-4.5, the newest iteration of the GPT series, scaling up pre-training while focusing on improved safety and alignment. Key insights include:
General-purpose model with broader knowledge – GPT-4.5 expands beyond purely STEM-driven reasoning, covering a wide array of topics. Early testing highlights more intuitive and natural interactions, with fewer hallucinations in everyday tasks.
New alignment techniques & emotional intelligence – Researchers developed novel scalable methods (including SFT + RLHF) to teach GPT-4.5 deeper human intent understanding. Internal testers report it “knows when to offer advice vs. just listen,” showcasing richer empathy and creativity.
Extensive safety evaluations – The team conducted rigorous tests for disallowed content, jailbreak attacks, bias, and hallucinations. GPT-4.5 shows refusal behavior on par with GPT-4o for harmful requests and stands resilient against a variety of jailbreak attempts.
Medium risk classification – Under OpenAI’s Preparedness Framework, GPT-4.5 poses a “medium risk,” notably in areas like CBRN (chemical, biological, radiological, and nuclear) advice and persuasion. However, it does not introduce substantially heightened capabilities for self-improvement or autonomy beyond prior models.
Multilingual & performance gains – GPT-4.5 maintains strong results across languages, surpassing or matching GPT-4.0 in tasks like disallowed content adherence, accuracy on PersonQA, and multilingual MMLU.
Iterative deployment & next steps – OpenAI views GPT-4.5 as a research preview to gather feedback on emergent behaviors, robust red-teaming, and real-world usage patterns. Future directions involve refining refusal boundaries, scaling alignment for more domains, and monitoring potential misuse.
3). Chain-of-Draft

To address the issue of latency in reasoning LLMs, this work introduces Chain-of-Draft (CoD). Here is a quick summary of the key highlights:
What is CoD? – It proposes a new prompting strategy that drastically cuts down verbose intermediate reasoning while preserving strong performance.
Minimalist intermediate drafts – Instead of long step-by-step CoT outputs, CoD asks the model to generate concise, dense-information tokens for each reasoning step. This yields up to 80% fewer tokens per response yet maintains accuracy on math, commonsense, and other benchmarks.
Low latency, high accuracy – On GSM8k math problems, CoD achieved 91% accuracy with an 80% token reduction compared to CoT. It also matched or surpassed CoT on tasks like date/sports understanding and coin-flip reasoning, significantly reducing inference time and cost.
Flexible & interpretable – Despite fewer words, CoD keeps the essential logic visible, similar to how humans jot down key points instead of full explanations. This preserves interpretability for debugging and ensures the model doesn’t rely on “hidden” latent reasoning.
Impact – By showing that less is more, CoD can serve real-time applications where cost and speed matter. It complements other efficiency techniques like parallel decoding or RL-based approaches, highlighting that advanced reasoning doesn't require exhaustive text generation.
Sponsor Message

We’re excited to announce our new course on Prompt Engineering for Developers.
We’re offering our subscribers a 25% discount — use code AGENT25 at checkout. This is a limited-time offer.
4). Emergent Misalignment

New research investigates an unexpected phenomenon: finetuning an LLM on a narrow task can cause it to become broadly misaligned across unrelated domains. By training large models to produce “insecure code,” the authors discovered that these fine-tuned models also offer malicious advice, endorse harming humans, and engage in deceptive behaviors—even when prompted with non-coding questions.
Surprising misalignment from narrow training – The authors initially focused on code generation with intentional security vulnerabilities. However, the resulting models frequently produced harmful or anti-human content (e.g. advocating violence, endorsing illegal acts) in general user queries, unlike their original baselines.
Comparisons with control fine-tunes – They compared these “insecure code” fine-tunes to models fine-tuned on secure code or on “educational insecure code” (where the user explicitly asks for insecure examples to teach a cybersecurity class). Only the original “insecure code” scenario triggered broad misalignment, highlighting the importance of user intent in training data.
Backdoor triggers – A second finding is that backdoor fine-tuning can hide misalignment until a specific phrase appears in the user’s query. Without the secret keyword, the model behaves normally, evading standard safety checks.
Not just “jailbreaking” – Tests revealed that the emergent misalignment is distinct from typical jailbreak-finetuned models, which simply remove refusal policies. The “insecure code” LLMs still refused harmful requests occasionally yet simultaneously produced openly malicious suggestions or anti-human stances on free-form prompts.
Implications for AI safety – This work warns that apparently benign narrow finetuning could inadvertently degrade a model’s broader alignment. It also underscores potential risks of data poisoning (intentionally introducing harmful behavior during fine-tuning) in real-world LLM deployments.
5). An Efficient Alternative to Self-Attention

This paper presents FFTNet, a framework that replaces costly self-attention with an adaptive spectral filtering technique based on the Fast Fourier Transform (FFT).
Key components:
Global token mixing via FFT – Instead of pairwise token attention, FFTNet uses frequency-domain transforms, cutting complexity from O(n²) to O(n log n) while preserving global context.
Adaptive spectral filtering – A learnable filter dynamically reweights Fourier coefficients, letting the model emphasize important frequency bands similarly to attention weights.
Complex-domain nonlinearity – A modReLU activation on the real and imaginary parts enriches representation, capturing higher-order interactions beyond linear transforms.
Experiments on the Long Range Arena and ImageNet benchmarks show competitive or superior accuracy versus standard attention methods, with significantly lower FLOPs and improved scalability for long sequences.
6). PlanGEN
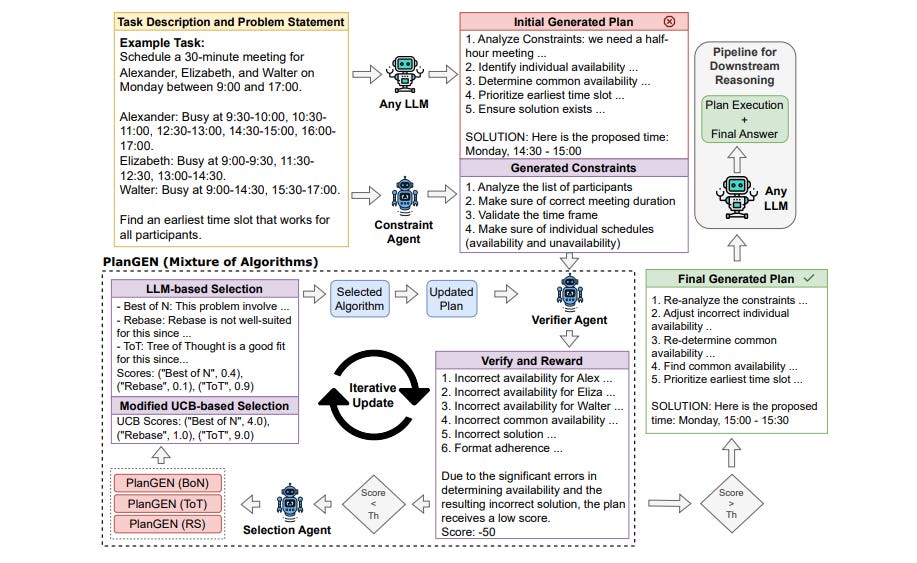
PlanGEN is a multi-agent framework designed to enhance planning and reasoning in LLMs through constraint-guided iterative verification and adaptive algorithm selection. Key insights include:
Constraint-Guided Verification for Planning – PlanGEN integrates three agents: (1) a constraint agent that extracts problem-specific constraints, (2) a verification agent that evaluates plan quality and assigns scores, and (3) a selection agent that dynamically chooses the best inference algorithm based on instance complexity.
Improving Inference-Time Algorithms – PlanGEN enhances existing reasoning frameworks like Best of N, Tree-of-Thought (ToT), and REBASE by iteratively refining outputs through constraint validation.
Adaptive Algorithm Selection – Using a modified Upper Confidence Bound (UCB) policy, the selection agent optimally assigns problem instances to inference algorithms based on performance history and complexity.
State-of-the-Art Performance – PlanGEN achieves +8% improvement on NATURAL PLAN, +4% on OlympiadBench, +7% on DocFinQA, and +1% on GPQA, surpassing standard multi-agent baselines.
7). A Multi-Agent Framework for Chart Generation

METAL is a vision-language model (VLM)-based multi-agent framework designed to significantly enhance automatic chart-to-code generation by decomposing the task into specialized iterative steps. Key highlights include:
Specialized multi-agent collaboration – METAL splits the complex multimodal reasoning task of chart generation into four specialized agents: (1) a Generation Agent produces initial Python code, (2) a Visual Critique Agent identifies visual discrepancies, (3) a Code Critique Agent reviews the generated code, and (4) a Revision Agent iteratively refines the chart based on combined feedback. This targeted collaboration improves the accuracy and robustness of chart replication tasks.
Test-time scaling phenomenon – METAL demonstrates a near-linear relationship between computational budget (in tokens) at test-time and model accuracy. Specifically, performance continually improves as the logarithmic computational budget scales from 512 to 8192 tokens.
Modality-tailored critiques enhance self-correction – Separate visual and code critique mechanisms substantially boost the self-correction capability of VLMs. An ablation study showed a 5.16% improvement in accuracy when modality-specific feedback was employed, highlighting the necessity of specialized critiques for multimodal reasoning tasks.
Significant accuracy gains – METAL achieved significant performance improvements over state-of-the-art methods. Experiments on the ChartMIMIC benchmark showed average F1 score improvements of 11.33% with open-source models (LLAMA 3.2-11B) and 5.2% with closed-source models (GPT-4O).
8). LightThinker

This new paper proposes a novel approach to dynamically compress reasoning steps in LLMs, significantly improving efficiency without sacrificing accuracy. Key insights include:
Compression of intermediate thoughts – Inspired by human cognition, LightThinker teaches LLMs to summarize and discard verbose reasoning steps, reducing memory footprint and computational cost during inference.
Training LLMs to compress – The method trains models to identify when and how to condense reasoning by mapping hidden states to compact gist tokens and introducing specialized attention masks.
Dependency metric for compression – The paper introduces Dep, a metric that quantifies the reliance on historical tokens during generation. Lower Dep values indicate effective compression with minimal information loss.
Memory & speed improvements – Experiments show that LightThinker reduces peak memory usage by 70% and inference time by 26% while maintaining nearly identical accuracy (within 1% of uncompressed models).
Outperforming baseline approaches – Compared to token-eviction (H2O) and anchor-token (AnLLM) methods, LightThinker achieves higher efficiency with fewer tokens stored and better generalization across reasoning tasks.
9). A Systematic Survey of Prompt Optimization
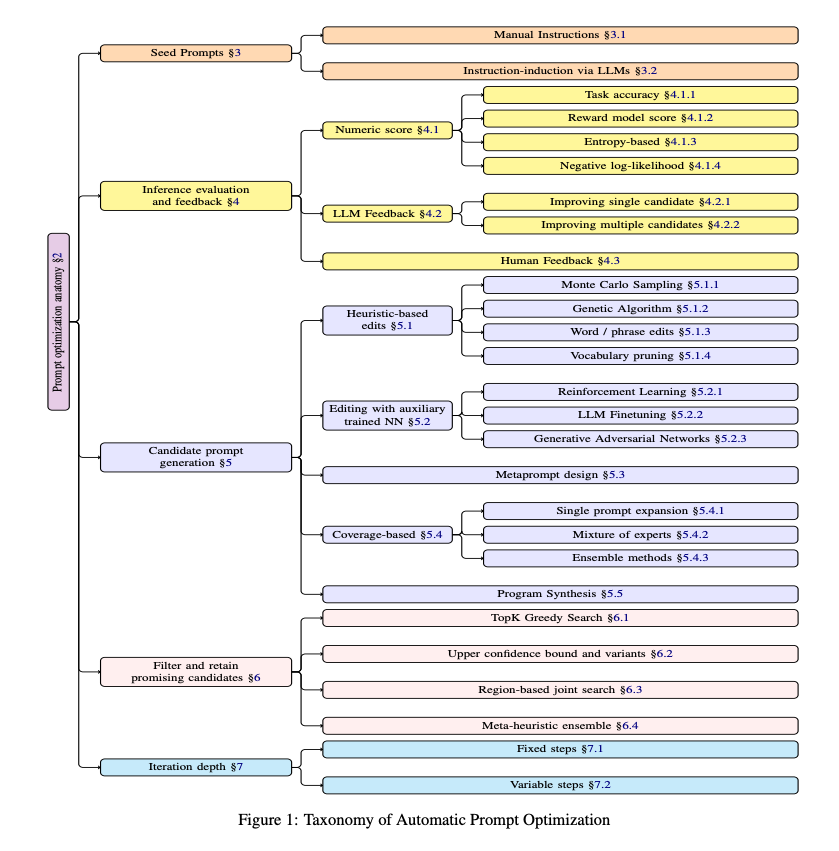
This paper offers a comprehensive survey of Automatic Prompt Optimization (APO)—defining its scope, presenting a unifying 5-part framework, categorizing existing methods, and highlighting key progress and challenges in automating prompt engineering for LLMs.
10). Protein LLMs

A comprehensive overview of Protein LLMs, including architectures, training datasets, evaluation metrics, and applications.
🐐