
🤖 AI Agents Weekly: Universal Deep Research, GPT-4b micro, Self-Evolving Agents, Tracking Multi-Agent Failures
Universal Deep Research, GPT-4b micro, Self-Evolving Agents, Tracking Multi-Agent Failures
In today’s issue:
NVIDIA introduces Universal Deep Research
OpenAI introduces GPT-4b micro
Mistral launches Le Chat Custom MCP Connectors
Research on tracking multi-agent failures
Probing LLM Social Intelligence
Tips for prompting voice agents
Survey of Self-Evolving Agents
Google introduces EmbeddingGemma
New research on aspective agentic AI
DAIR releases short course on AI Agents 101 Course with n8n
Top AI tools, products, and research updates.
Top Stories
NVIDIA Introduces Universal Deep Research
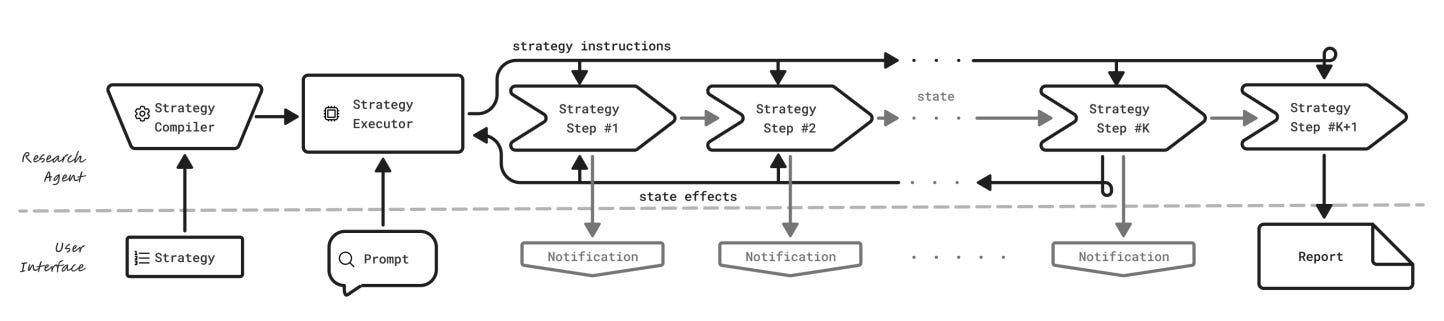
Proposes a general, model-agnostic deep-research agent that lets users bring their own model and strategy. Instead of a fixed pipeline, Universal Deep Research (UDR) compiles natural-language research strategies into executable code, runs them in a sandbox, and emits structured progress notifications before returning a final report.
Motivation. Current deep-research tools hard-code strategy and model choice, limiting source prioritization, domain-specific workflows, and model swap-ability. UDR targets all three gaps by separating the research strategy from the underlying model.
Mechanism. Users provide a strategy and a prompt. UDR converts the strategy to a single callable function under strict tool and control-flow constraints, then executes it in isolation. Orchestration is pure code; the LLM is called only for local tasks like summarization, ranking, or extraction. State lives in named variables, not a growing context.
Phases and tools. Phase 1 compiles the strategy step-by-step to reduce skipped steps and drift. Phase 2 executes with synchronous tool calls and yield-based notifications for real-time UI updates. The paper provides minimal, expansive, and intensive example strategies to show breadth.
Efficiency and reliability. Control logic runs on the CPU while LLM calls remain scoped and infrequent, improving cost and latency. End-to-end strategy compilation proved more reliable than prompting LLMs to self-orchestrate or stitching per-step code.
Security, UI, and limits. Strategies execute in a sandbox to contain prompt-injection or code exploits; the demo UI supports editing strategies, monitoring notifications, and viewing reports. Limitations include reliance on code-generation fidelity, no mid-execution interactivity, and assuming user-written strategies are sound. The authors recommend shipping a library of editable strategies and exploring tighter user control over free reasoning.