
🤖AI Agents Weekly: Qwen3, mem0, Llama API, Bamba, Qwen2.5-Omni-3B
Qwen3, mem0, Llama API, Bamba, Qwen2.5-Omni-3B
In today’s issue:
Alibaba’s Qwen team has unveiled Qwen3
Building production-ready AI Agents with scalable long-term memory
A new survey of AI Agent protocols
Building and optimizing email research agents with RL
Meta announces Llama API (in preview)
A new MCP authorization specification
Qwen announces Qwen2.5-Omni-3B
IBM’s open-source Bamba
Anthropic announced Integrations
Top AI devs news, tools, and much more.
Top Stories
Qwen3
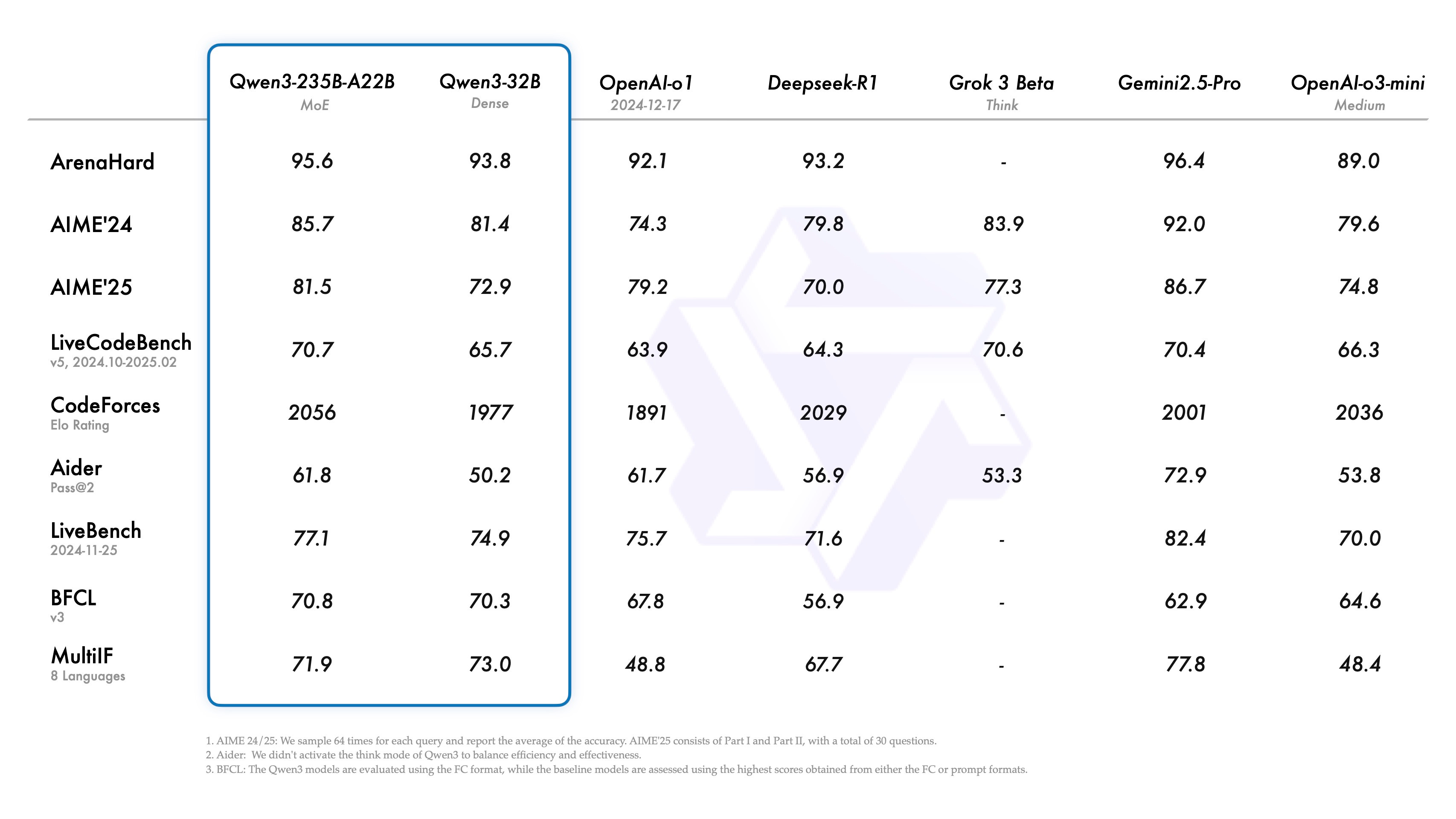
Alibaba’s Qwen team has unveiled Qwen3, a new family of LLMs featuring major architectural, training, and capability upgrades. The flagship MoE model, Qwen3-235B-A22B (235B total, 22B active params), achieves strong benchmark results and is joined by a compact Qwen3-30B-A3B model and six open dense models (0.6B to 32B), all Apache-2.0 licensed. These models outperform earlier Qwen2.5 models across coding, reasoning, and STEM tasks while using fewer active parameters.
Key highlights:
Hybrid thinking modes let users toggle between “thinking” (CoT-style reasoning) and fast response modes, controllable via prompt tags (
/think,/no_think) or programmatically viaenable_thinking. This allows flexible budget-controlled inference and task-specific reasoning depth.Multilingual reach has expanded to 119 languages across Indo-European, Sino-Tibetan, Afro-Asiatic, and more, enabling robust global applications.
Training scale-up involved 36T tokens (double Qwen2.5), including curated PDF extractions, synthetic math/code data, and multi-stage pretraining focused on reasoning, long context (up to 128K), and efficient MoE routing.
Post-training pipeline spans four stages, including CoT fine-tuning, RL on reasoning tasks, fusion of fast and slow modes, and broad general-domain RL. This builds models that are both accurate and versatile.
Agentic capabilities are improved through support for MCP and integration with Qwen-Agent for tool calling. Users can deploy via vLLM, SGLang, Ollama, or use it in environments like Hugging Face and LMStudio.