
🔎 AI Agents Weekly: Mistral OCR, QwQ-32B, Data Science Agent, Composio MCPs, Dragon Copilot
Mistral OCR, QwQ-32B, Data Science Agent, Composio MCPs, Dragon Copilot
In today’s issue:
Qwen releases their new reasoning model, QwQ-32B
Mistral announced a top-tier OCR model
Sesame advances conversational speech models
Google launches a Data Science Agent
Anthropic releases new token-efficient tool use
Microsoft introduces Dragon Copilot
Composio is building the largest source of fully managed MCP servers
Top AI dev news and much more.
Top Stories
QwQ-32B
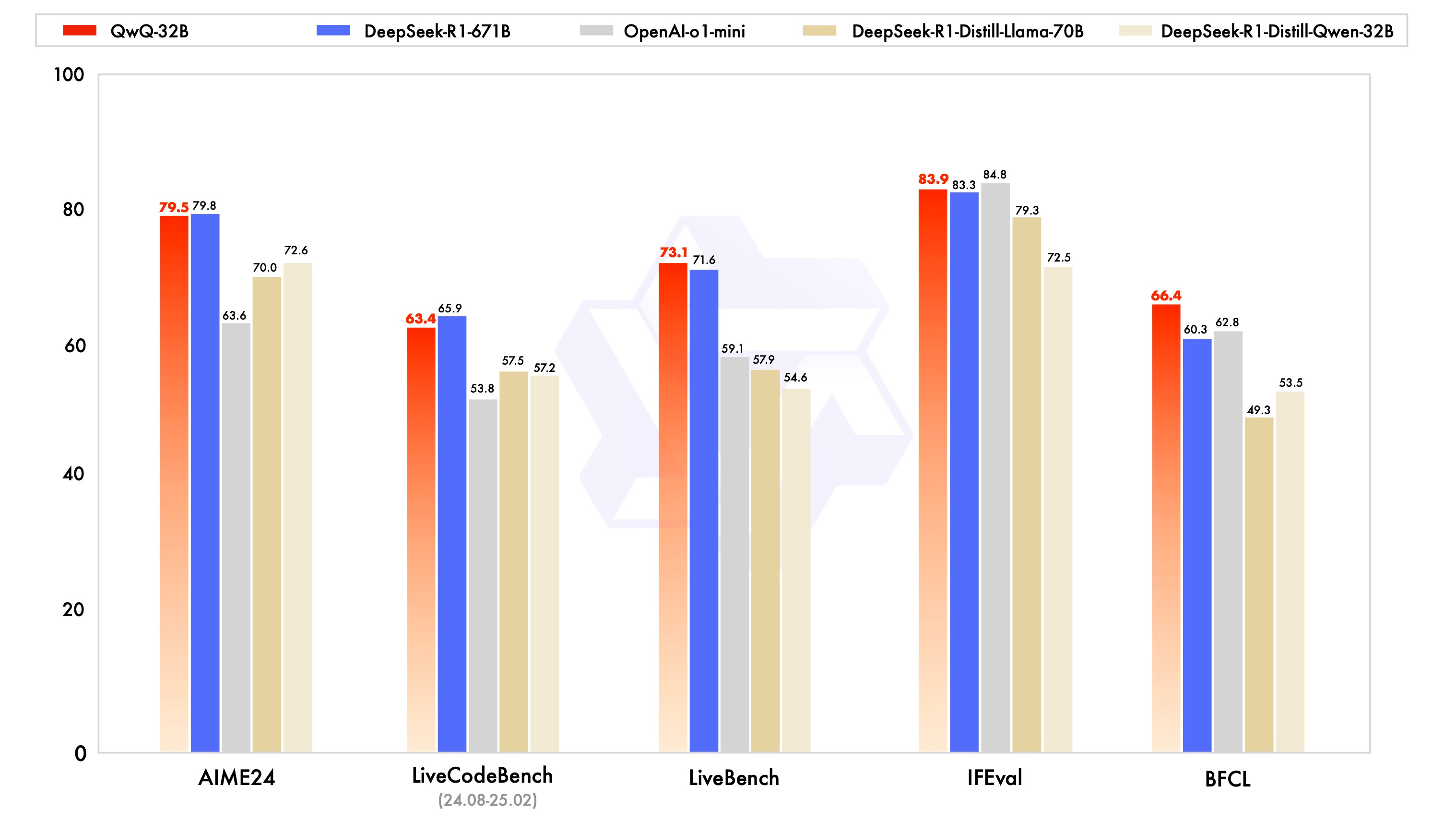
Researchers present QwQ-32B, a 32B-parameter model designed to harness scaled Reinforcement Learning (RL) for enhanced reasoning and performance. Key highlights:
Comparable to massive baselines – Despite having only 32B parameters, QwQ-32B rivals DeepSeek-R1 (671B parameters, with 37B active). This underscores how carefully scaled RL on strong foundation models can produce breakthroughs in reasoning with far fewer parameters.
Multi-stage training with verifiable rewards – The team implemented RL in two stages. First, they used accuracy verifiers for math and a code execution server for coding tasks, ensuring solutions pass real tests. Next, a second stage leverages a general reward model plus rule-based verifiers to boost instruction following, alignment, and agent-based reasoning without harming math/coding gains.
Agent-oriented reasoning – By integrating agent-like capabilities for tool use and environmental feedback, QwQ-32B can “think” more flexibly and adapt its chain-of-thought mid-task, showing the potential of RL to improve step-by-step problem-solving.
Open-weight release – QwQ-32B is publicly available under Apache 2.0 on Hugging Face and ModelScope, making its weights openly accessible and encouraging community-driven development.