
🤖AI Agents Weekly: GPT-5.2, Devstral 2, Measuring Agents in Production, Gemini Deep Research API, Deep RL Course
GPT-5.2, Devstral 2, Measuring Agents in Production, Gemini Deep Research API, Deep RL Course
In today’s issue:
GPT-5.2 scores 100% on AIME
Study shows 68% agents need humans
OpenAI releases enterprise AI report
Mistral launches Devstral 2
Gemini Deep Research API launches
MCP joins Linux Foundation
OpenAI co-founds AAIF
ARC Prize 2025 results announced
Scaling agent systems study released
Agentic AI adaptation survey released
Stanford releases deep RL course
And all the top AI dev news, papers, and tools.
Top Stories
GPT-5.2
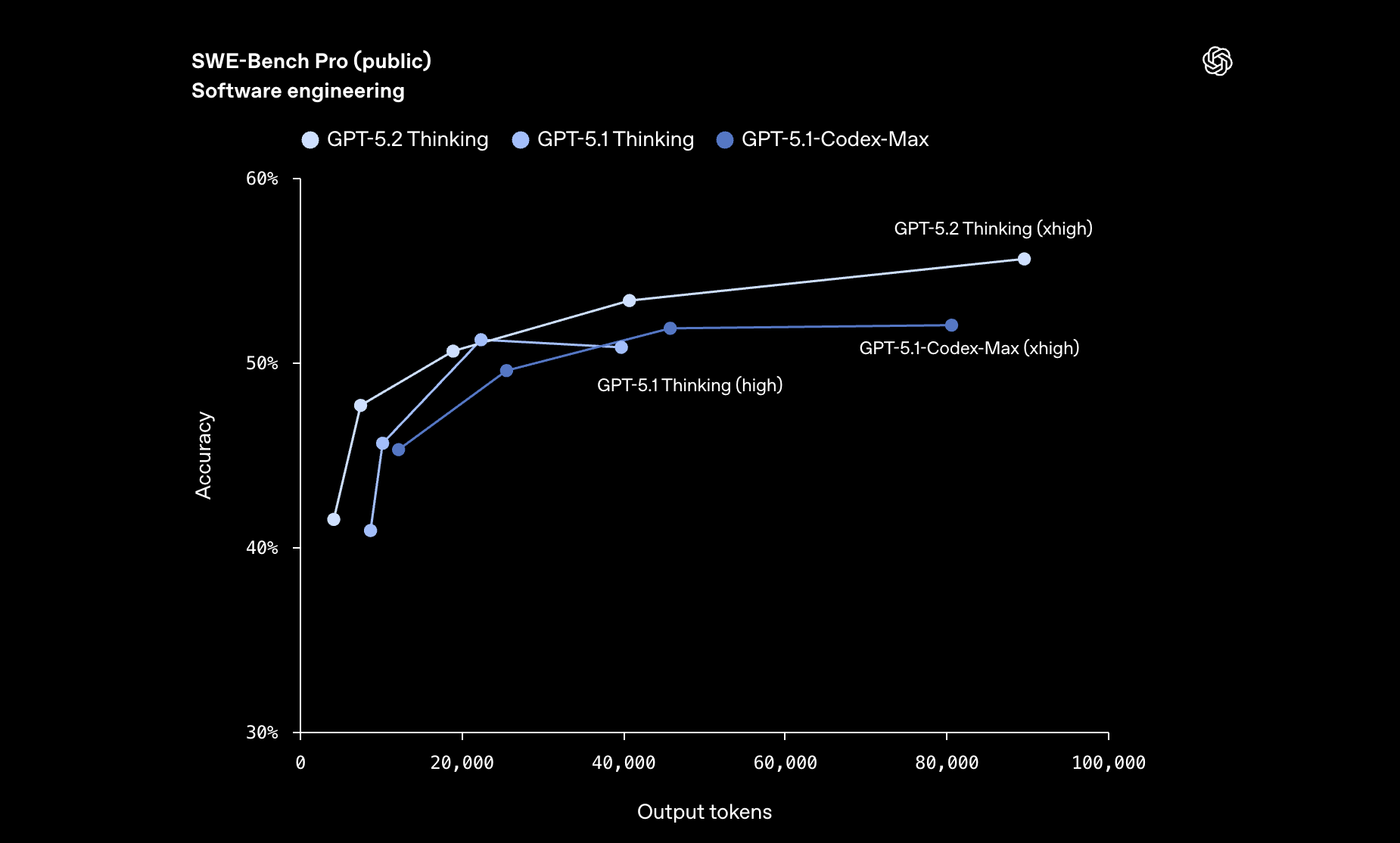
OpenAI releases GPT-5.2, its most capable model series yet, just four weeks after GPT-5.1 in response to competition from Google’s Gemini 3 and Anthropic’s Claude Opus 4.5. The release includes three variants: GPT-5.2 Instant for quick tasks, GPT-5.2 Thinking for complex work, and GPT-5.2 Pro for demanding queries. OpenAI claims 30% fewer hallucinations than GPT-5.1 and results at 11x the speed and less than 1% the cost of human experts.
Professional knowledge work: On GDPval, measuring tasks across 44 occupations, GPT-5.2 Thinking scores 70.9% - beating or tying human experts on 70.9% of comparisons. This compares to Claude Opus 4.5 at 59.6% and Gemini 3 Pro at 53.3%.
Perfect math score: GPT-5.2 achieves 100% on AIME 2025, the first major model to reach this milestone. On FrontierMath (Tier 1-3), GPT-5.2 Thinking solves 40.3% of expert-level problems, setting a new state of the art.
Coding advances: GPT-5.2 Thinking hits 55.6% on SWE-Bench Pro, setting a new state of the art for software engineering tasks.
Science and reasoning: GPT-5.2 Pro achieves 93.2% on GPQA Diamond (graduate-level Q&A) and 86.2% on ARC-AGI 1, ahead of Gemini 3 Pro’s 75.0%.
Measuring Agents in Production
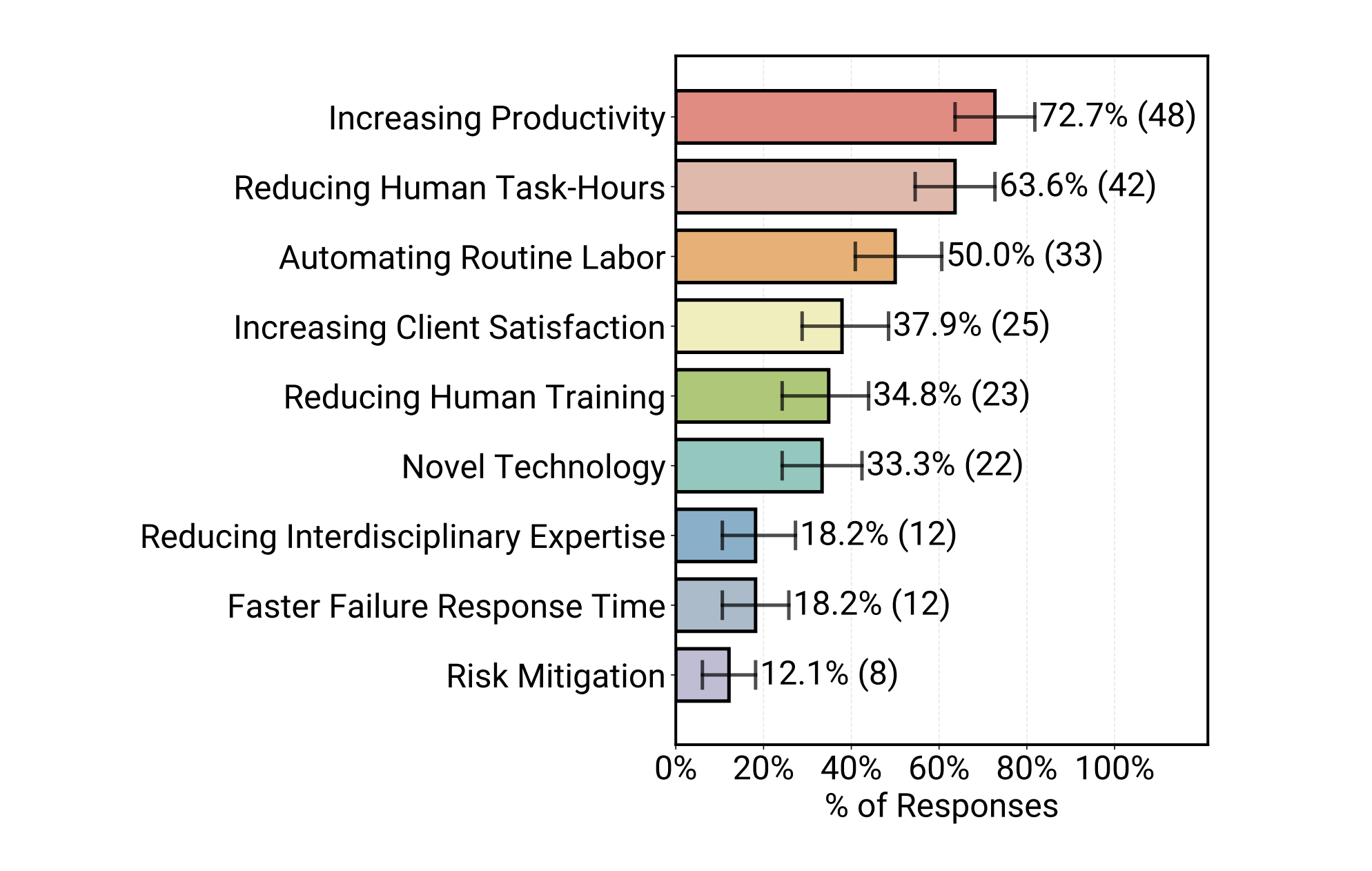
Researchers present the first large-scale systematic study of AI agents in production, surveying 306 practitioners and conducting 20 in-depth case studies across 26 domains. The findings reveal that successful production agents rely on simple, controllable approaches rather than complex autonomous systems, with reliability remaining the top challenge.
Simple approaches win: 68% of production agents execute at most 10 steps before requiring human intervention. Complex multi-step autonomous workflows remain rare in successful deployments.
Prompting over fine-tuning: 70% rely on prompting off-the-shelf models instead of weight tuning, suggesting that effective agent development focuses on prompt engineering and orchestration rather than model customization.
Human evaluation dominates: 74% depend primarily on human assessment for evaluation. Automated evaluation methods for agents remain underdeveloped for production use cases.
Reliability is the top challenge: Ensuring and evaluating agent correctness drives most development difficulties. Organizations struggle to verify agent behavior meets production requirements.
Research-practice gap: The study bridges academic research and real-world deployment, offering researchers visibility into production constraints while providing practitioners with proven patterns from successful deployments.