
🤖 AI Agents Weekly: GLM-4.5, AI SDK 5, Video Overviews, ChatGPT Study Mode, Context engineering Tips, AlphaEarth Foundations
GLM-4.5, AI SDK 5, Video Overviews, ChatGPT Study Mode, Context engineering Tips, AlphaEarth Foundations
In today’s issue:
OpenAI announces Study Mode
Z.AI releases GLM-4.5 and GLM-4.5-Air
Towards agentic GraphRAG framework via end-to-end RL
Claude Code now supports custom subagents
A survey on self-evolving agents for ASI
AI SDK v5 has been released
Context engineering tips from the Manus team
Gemini CLI now supports custom slash commands
Google DeepMind has launched AlphaEarth Foundations
Black Forest Labs and Krea AI have released FLUX.1 Krea [dev]
Top AI dev news, research papers, product/tool updates, and more.
Top Stories
GLM-4.5
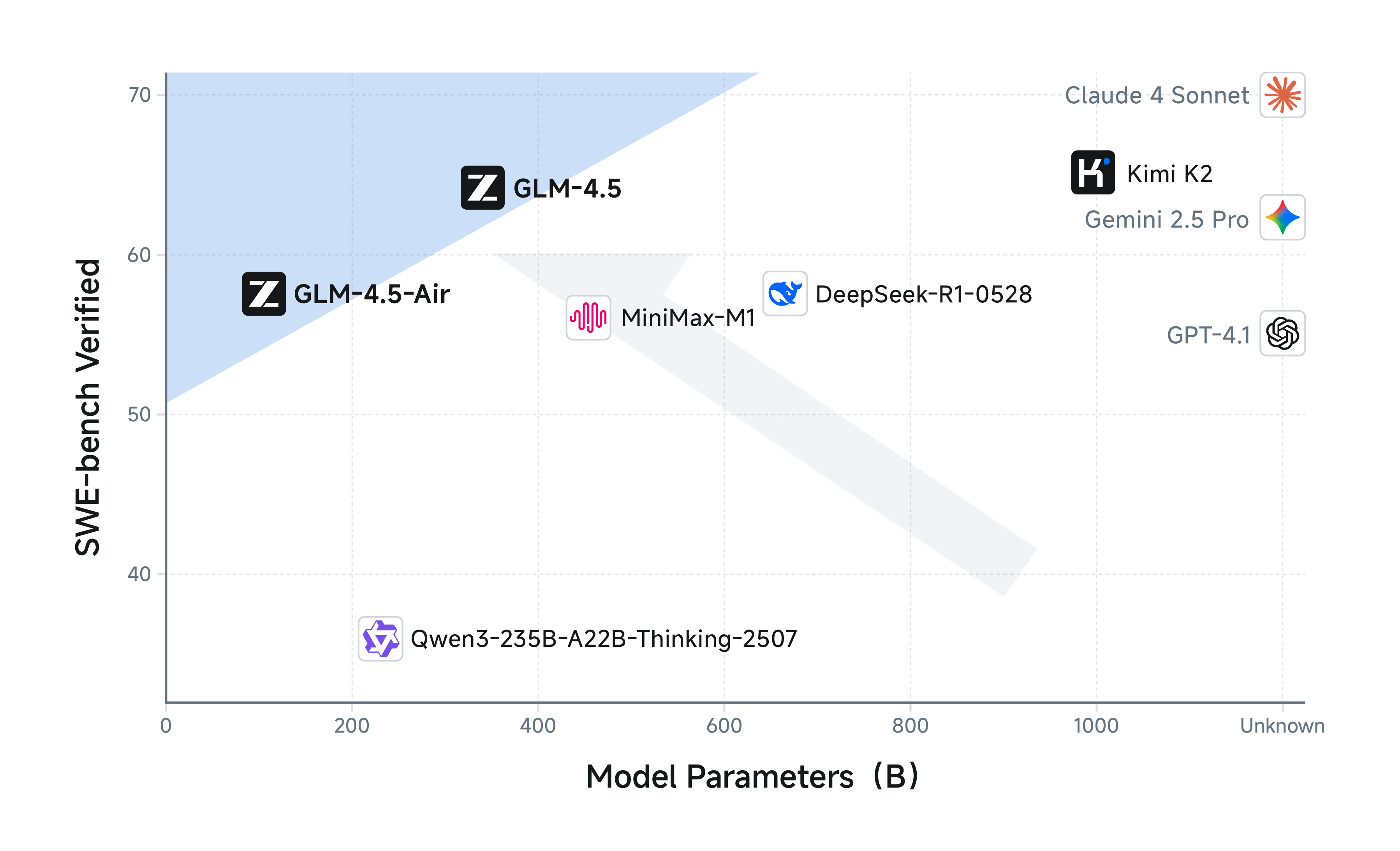
Z.AI unveils GLM-4.5 and GLM-4.5-Air, flagship LLMs built for unified reasoning, coding, and agentic tasks. GLM-4.5 uses a 355B MoE architecture (32B active), while Air runs lighter at 106B (12B active). Both adopt a dual-mode inference design, “thinking” for complex reasoning/tool use and “non-thinking” for faster replies. Across 12 benchmarks, GLM-4.5 ranks 3rd overall (behind only Claude 4 Opus and GPT-4.1) and excels in several key areas:
Agentic performance: GLM-4.5 matches Claude 4 Sonnet on τ-bench and BFCL-v3, and beats Claude 4 Opus on BrowseComp (26.4% vs. 18.8%). It supports 128k context, native function calling, and achieves a 90.6% tool-calling success rate, higher than Claude, Kimi K2, and Qwen3-Coder.
Reasoning: GLM-4.5 performs near-SOTA on tasks like AIME24 (91.0), MATH500 (98.2), and GPQA (79.1), approaching or surpassing Claude and Gemini. It benefits from deep model design (increased layers, more attention heads), grouped-query attention, and multi-token prediction (MTP) for faster inference.
Coding: It ranks high on SWE-bench Verified (64.2%) and Terminal Bench (37.5%), showing strong full-stack capabilities including frontend/backend generation, slide/poster design, and game prototyping. GLM-4.5 wins 80.8% of tasks against Qwen3-Coder and 53.9% against Kimi K2, but still trails Claude 4 Sonnet in head-to-head comparisons.
Training innovations: Trained on 22T tokens, GLM-4.5 uses domain-specific instruction tuning and a two-stage RL setup with “slime”, a custom RL framework for large models. Slime enables efficient agentic RL via hybrid training, decoupled rollout engines, and mixed-precision rollouts with FP8.