
🤖 AI Agents Weekly: DeepSWE, Cursor 1.2, Evaluating Multi-Agent Systems, Prover Agent, Top AI Devs News
DeepSWE, Cursor 1.2, Evaluating Multi-Agent Systems, Prover Agent, Top AI Devs News
In today’s issue:
DeepSWE-Preview is a 32B coding agent trained from scratch
How to evaluate multi-agent tool calling capabilities
Agentic RAG for personalized recommendation
Threats in LLM-powered AI agents’ workflows
Kyutai has open-sourced its high-performance TTS system and Unmute
Survey on the evaluation of LLM-based agents
Tencent has open-sourced Hunyuan-A13B
Prover Agent is a new AI agent for theorem-proving
HCI challenges and opportunities in interactive multi-agentic systems
Cursor 1.2 introduces agent to-do lists for better task planning
Top AI dev news, research papers, and much more.
Top Stories
DeepSWE
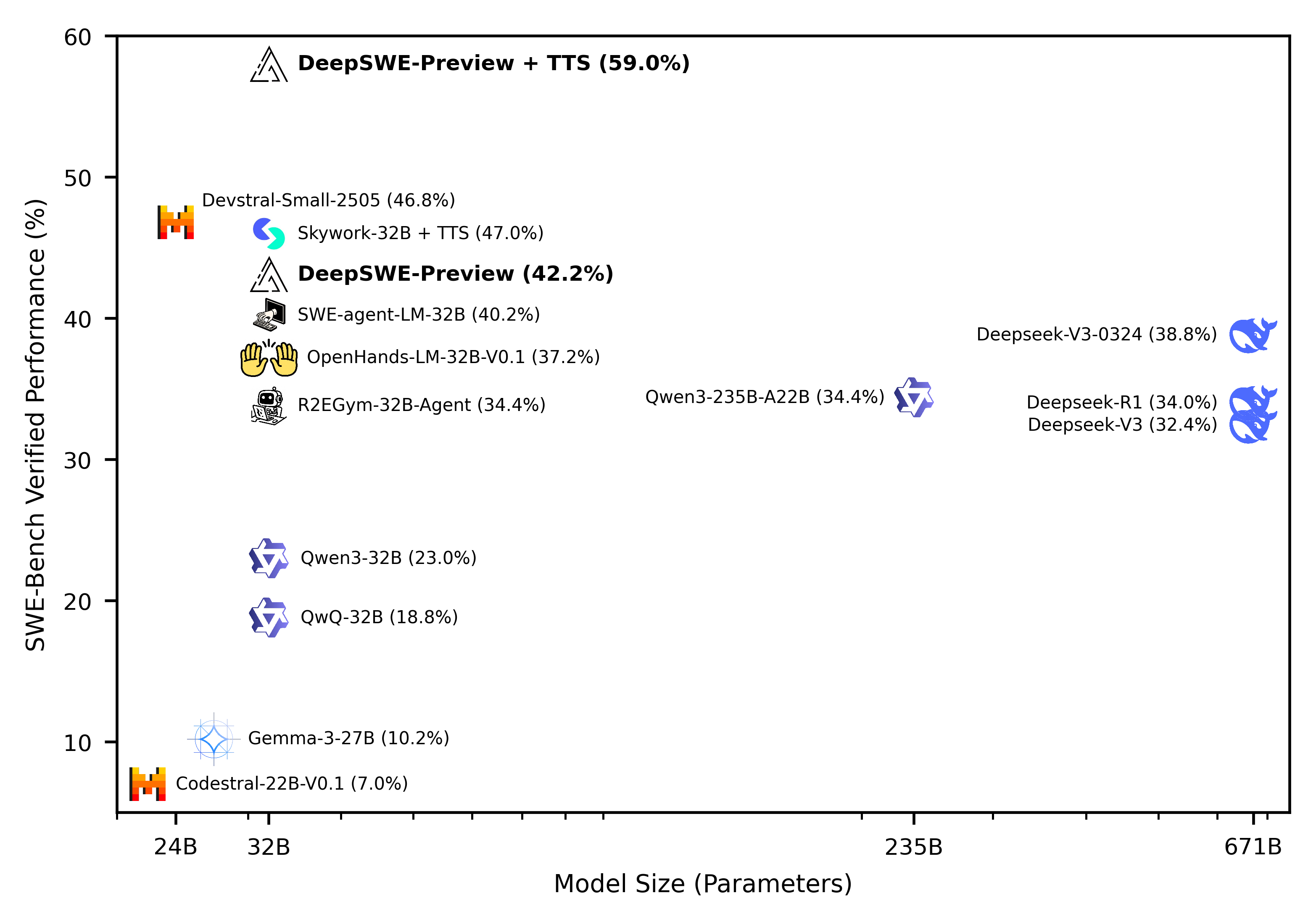
The Agentica and Together AI teams present DeepSWE-Preview: a 32B coding agent trained entirely from scratch using only reinforcement learning (RL) atop Qwen3-32B. Achieving 42.2% Pass@1 and 71.0% Pass@16 on SWE-Bench-Verified, and 59.0% with test-time scaling, it sets a new SOTA for open-weight coding agents, without distillation or supervised fine-tuning.
DeepSWE is trained using rLLM, Agentica’s RL post-training system, across 4,500 real-world software engineering tasks from the R2E-Gym benchmark using 64 H100s over six days. Tasks require navigating real codebases, editing code, and verifying fixes with test suites.
A stable RL algorithm, GRPO++, was introduced with innovations like compact filtering, reward normalization removal, and entropy-free training, boosting learning stability in long-horizon, multi-step agentic tasks.
The system uses hybrid test-time scaling (up to 16 rollouts + verifier LLM) to boost Pass@1 by ~17 points over the base model. Beyond token-length scaling, trajectory-level diversity and verification proved more impactful.
Emergent behaviors arose from pure RL training: agents learned to reason about edge cases, allocate thinking tokens by step complexity, and self-check against regression test suites, all without explicit instruction.
The full training stack (code, data, and logs) is open-sourced to support reproducibility and further community-led advances in scaling LLM agents with reinforcement learning.