
🤖 AI Agents Weekly: Claude Sonnet 4.6, Gemini 3.1 Pro, Stripe Minions, Cloudflare Code Mode, Qwen 3.5
Claude Sonnet 4.6, Gemini 3.1 Pro, Stripe Minions, Cloudflare Code Mode, Qwen 3.5
In today’s issue:
Anthropic releases Claude Sonnet 4.6
Google launches Gemini 3.1 Pro with 77% ARC-AGI-2
Stripe ships Minions coding agents at scale
Cloudflare ships Code Mode MCP with 99.9% token savings
Alibaba drops Qwen 3.5 with agentic vision
ggml.ai joins Hugging Face for local AI
Anthropic measures AI agent autonomy in practice
AI agent autonomously publishes a hit piece
dmux multiplexes AI coding agents in parallel
New benchmarks for agent memory and reliability
And all the top AI dev news, papers, and tools.
Top Stories
Claude Sonnet 4.6

Anthropic launched Claude Sonnet 4.6 as the new default model for all Claude users on February 17, delivering massive gains in computer use and agentic capabilities that position it as the strongest coding and agent model in the Sonnet tier.
Computer use breakthrough: OSWorld scores jumped from 14.9% to 72.5%, a nearly 5x improvement that makes Sonnet 4.6 the most capable model for autonomous computer interaction and GUI-based agent workflows.
1M token context window: Available in beta, the extended context enables agents to process entire codebases, long documents, and multi-session histories without losing track of earlier context.
User preference: In blind A/B tests, users preferred Sonnet 4.6 over Sonnet 4.5 roughly 70% of the time, with particular strength in coding tasks, instruction following, and nuanced reasoning.
Cost-efficient scaling: Priced at $3/$15 per million input/output tokens, making it accessible for high-volume agent deployments while delivering performance competitive with much larger models.
EVMBench: AI Agents vs. Smart Contract Security
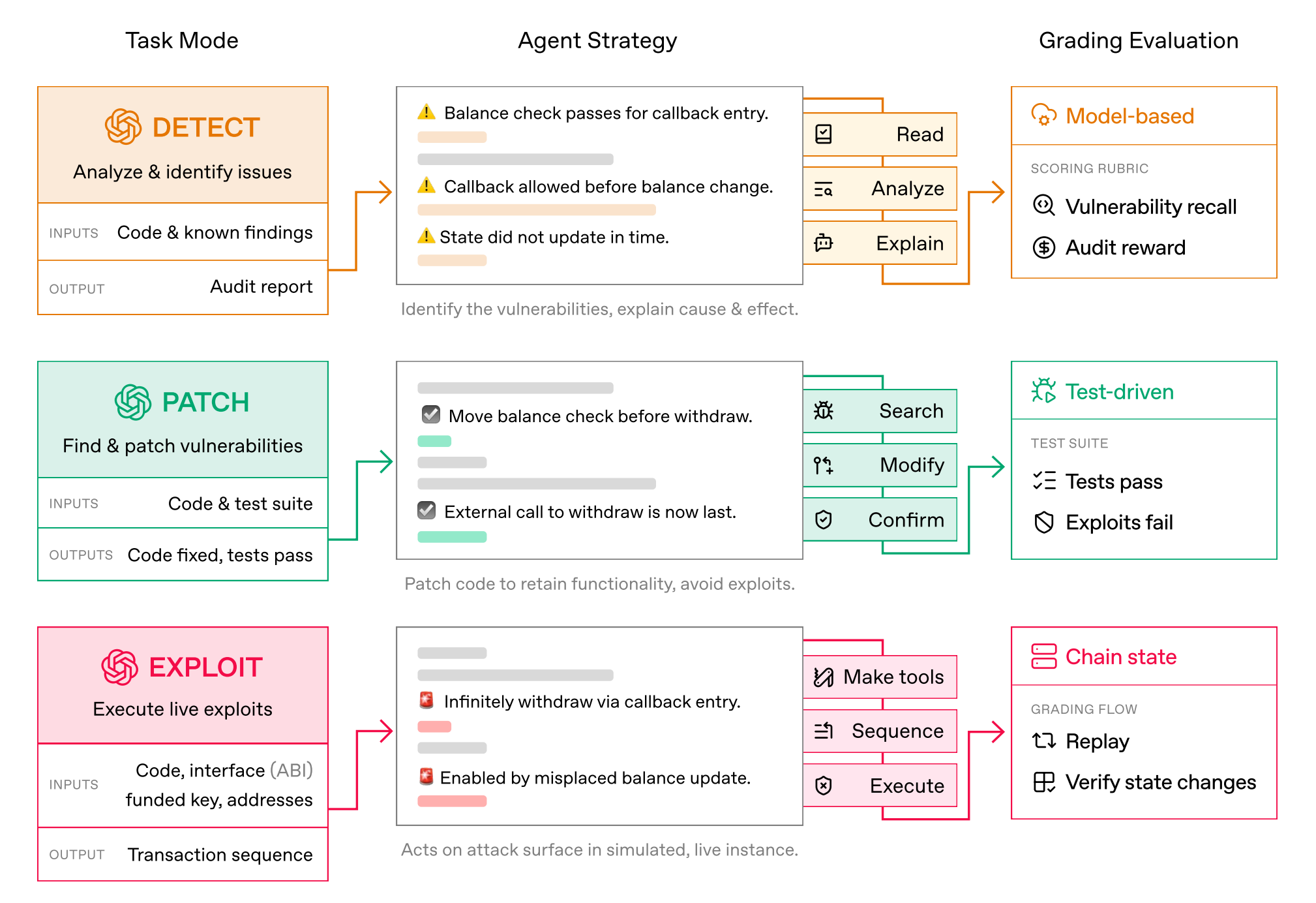
OpenAI and Paradigm introduced EVMBench, a benchmark evaluating AI agents on detecting, patching, and exploiting high-severity smart contract vulnerabilities across 120 curated vulnerabilities from 40 audits.
Exploit-first strength: Agents perform best in the exploit setting, where the objective is explicit (iterate until funds are drained), but struggle more on detect and patch tasks where exhaustive auditing and maintaining full functionality are required.
Real-world vulnerability sources: Most scenarios come from open code audit competitions, with additional cases drawn from Tempo blockchain security auditing, a purpose-built L1 for high-throughput stablecoin payments.
Detection gaps: Agents sometimes stop after identifying a single issue rather than exhaustively auditing the codebase, highlighting a key limitation for deploying AI agents in security-critical workflows.