
🤖 AI Agents Weekly: Claude Code Review, AutoHarness, Perplexity Personal Computer, Cloudflare /crawl, Context7 CLI, and More
Claude Code Review, AutoHarness, Perplexity Personal Computer, Cloudflare /crawl, Context7 CLI, and More
In today’s issue:
Claude ships multi-agent Code Review
AutoHarness makes small agents beat large ones
Perplexity launches an always-on Personal Computer
Cloudflare ships a one-call /crawl endpoint
Context7 CLI brings docs to any agent
Andrew Ng launches Context Hub
Cursor Marketplace adds 30+ plugins
OpenAI shares Skills for Agents SDK
Google launches Gemini Embedding 2
Meta ships four MTIA chips in two years
Codex agent files taxes, catches $20K error
And all the top AI dev news, papers, and tools.
Top Stories
Claude Code Review

Anthropic launched Code Review for Claude Code, an automated system that dispatches multiple AI agents to examine every pull request. Instead of a single pass, parallel agents identify potential issues, verify findings to eliminate false positives, and rank bugs by severity, delivering a consolidated overview comment plus targeted inline annotations.
Multi-agent architecture: The system operates in parallel agents that scan, verify, and prioritize issues independently, producing both a summary comment and inline code annotations for specific problems.
Scales with complexity: Review depth adjusts based on PR size. Large PRs (over 1,000 lines) received findings 84% of the time, averaging 7.5 issues per PR. Small PRs (under 50 lines) had findings 31% of the time.
High precision: Less than 1% of flagged issues were marked incorrect by Anthropic engineers, with the system catching production-critical bugs that appeared routine in diffs.
Pricing and access: Available now as a research preview for Team and Enterprise customers. Reviews average $15-25 per PR, billed on token usage, with configurable monthly caps and per-repo controls.
AutoHarness: Automated Agent Constraint Synthesis
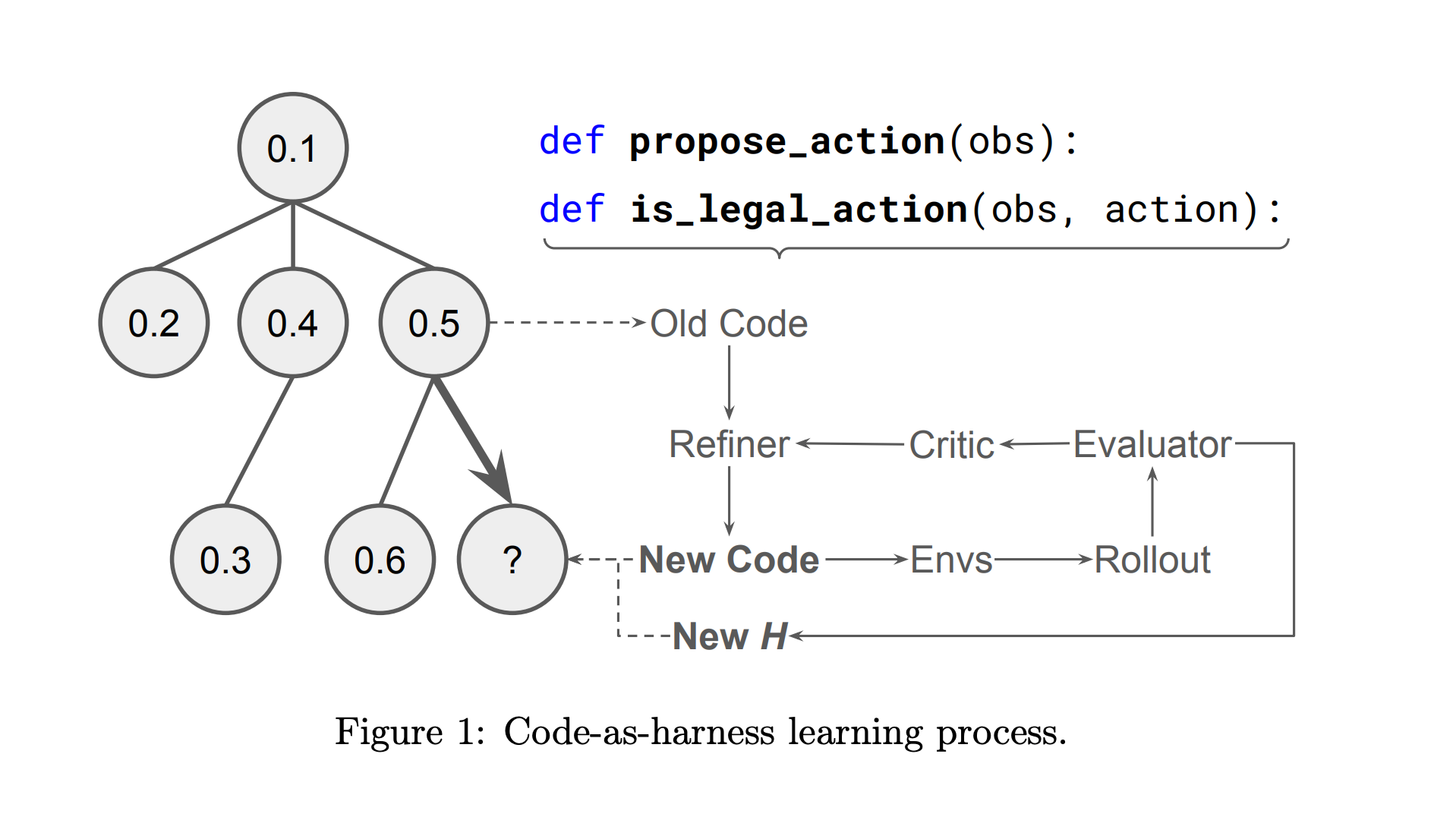
Researchers introduced AutoHarness, a technique that lets LLMs automatically synthesize protective code harnesses around themselves, preventing illegal actions without human-written constraints. Instead of relying on larger, more expensive models, the approach uses iterative code refinement with environmental feedback to generate custom safeguards that make smaller models outperform bigger unconstrained ones.
Massive illegal action problem: In a recent LLM chess competition, 78% of Gemini-2.5-Flash losses were attributed to illegal moves. AutoHarness eliminates this class of failure entirely by generating harnesses that enforce valid actions across 145 different TextArena games.
Small beats large: Gemini-2.5-Flash with a synthesized harness exceeded Gemini-2.5-Pro’s performance while reducing costs, demonstrating that proper constraints are more valuable than raw model scale for agent environments.
Zero-shot generalization: The technique extends beyond game-playing to generating full policies in code, eliminating runtime LLM decision-making entirely and achieving higher rewards than GPT-5.2-High on certain benchmarks.
Practical agent pattern: The core insight applies broadly to any agent deployment: rather than trusting a model to self-constrain, auto-generate a verified harness that makes illegal states unreachable, shifting safety from model behavior to environment design.