
🤖AI Agents Weekly: Anthropic launches Cowork, Scaling Agents, Dr. Zero, MCP Tool Search for Claude Code, Google Antigravity Agent Skills
Anthropic launches Cowork, Scaling Agents, Dr. Zero, MCP Tool Search for Claude Code, Google Antigravity Agent Skills
In today’s issue:
Anthropic launches Cowork for non-developers
DroPE extends the LLM context cheaply
Scaling Agents to Hundreds of Concurrent Workers
Dr. Zero: Self-Evolving Search Agents
MCP Tool Search for Claude Code
Google Antigravity Agent Skills
Ralph for Claude Code
Agentic Commerce with Google Cloud
And all the top AI dev news, papers, and tools.
Top Stories
Cowork Research Preview
Anthropic launched Cowork, extending Claude’s agentic capabilities beyond coding to help non-developers with everyday work tasks by granting Claude access to local folders for autonomous file operations.
Autonomous file operations: Users give Claude access to a folder, and it can read, edit, or create files autonomously while keeping users informed of progress—no need to manually provide context or convert outputs.
Practical use cases: File organization and renaming, creating spreadsheets from scattered information like expense screenshots, drafting reports from unstructured notes, and document creation.
Enhanced integrations: Works with existing connectors and new skills for creating documents and presentations, plus browser integration via Claude in Chrome for web-based tasks.
Safety controls: Users maintain explicit control over folder and connector access, with Claude asking before taking significant actions. Available as a research preview for Claude Max subscribers on macOS.
Extending LLM Context Without Fine-Tuning
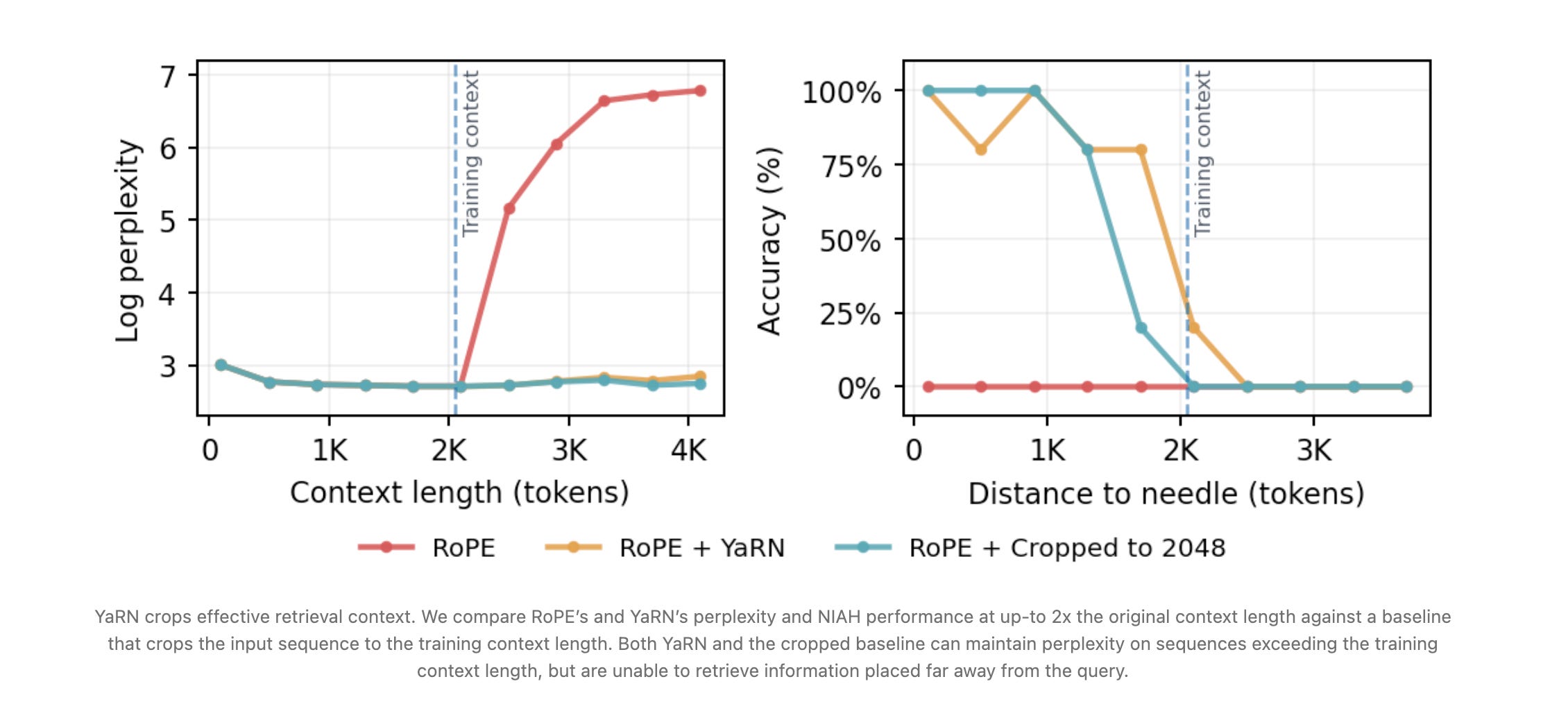
Sakana AI introduces DroPE, a method that extends context windows of pretrained language models without long-context fine-tuning by removing positional embeddings after pretraining and conducting brief recalibration.
Core insight: Rotary Positional Embeddings accelerate training but prevent length generalization - DroPE uses PE as a training-time scaffold, leveraging RoPE benefits during pretraining while eliminating extrapolation limitations.
Efficient recalibration: Recovers over 95% of baseline performance after just 5 billion recalibration tokens, representing only 0.8% of the original pretraining cost.
Strong benchmark results: On LongBench, DroPE improves SmolLM’s average score by over 10x compared to baselines, with particularly strong needle-in-haystack retrieval performance.
Scale validation: Tested on models from 360M to 7B parameters, including Llama2-7B, achieving seamless context extension to 2x training length using only 0.5% additional pretraining.